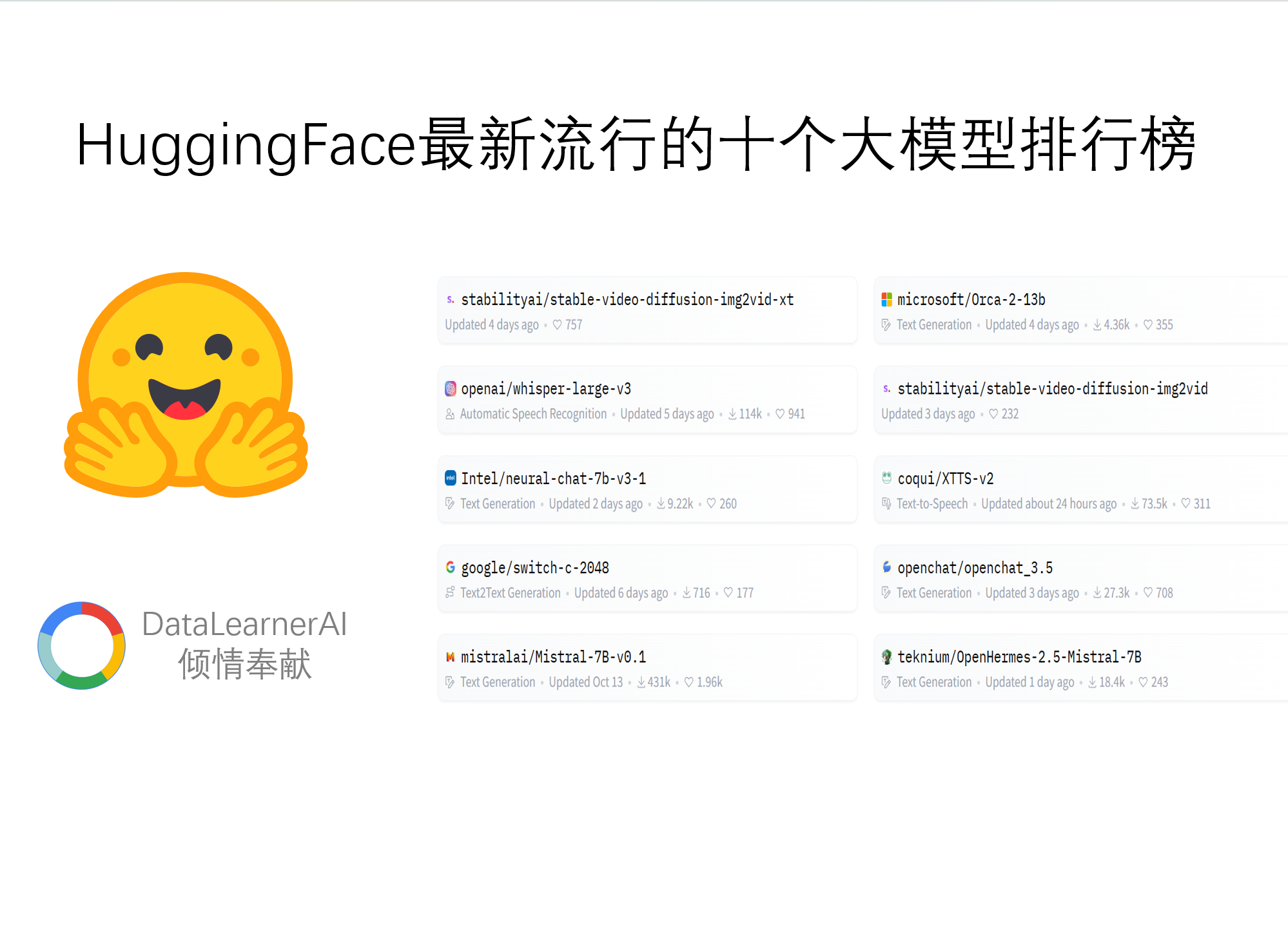
通俗易懂地解释OpenAI Sora视频生成的特点有哪些?Sora与此前的Stable Video Diffusion、Runway Gen2、Pika等有什么区别?OpenAI Sora的缺点是什么?
OpenAI的Sora模型是最近两天最火热的模型。它生成的视频无论是清晰度、连贯性和时间上都有非常好的结果。在Sora之前,业界已经有了很多视频生成工具和平台。但为什么Sora可以引起如此大的关注?Sora生成的视频与此前其它平台生成的视频到底有哪些区别?有很多童鞋似乎对这些问题依然有疑问,本文将以通俗的语言解释Sora的独特之处。