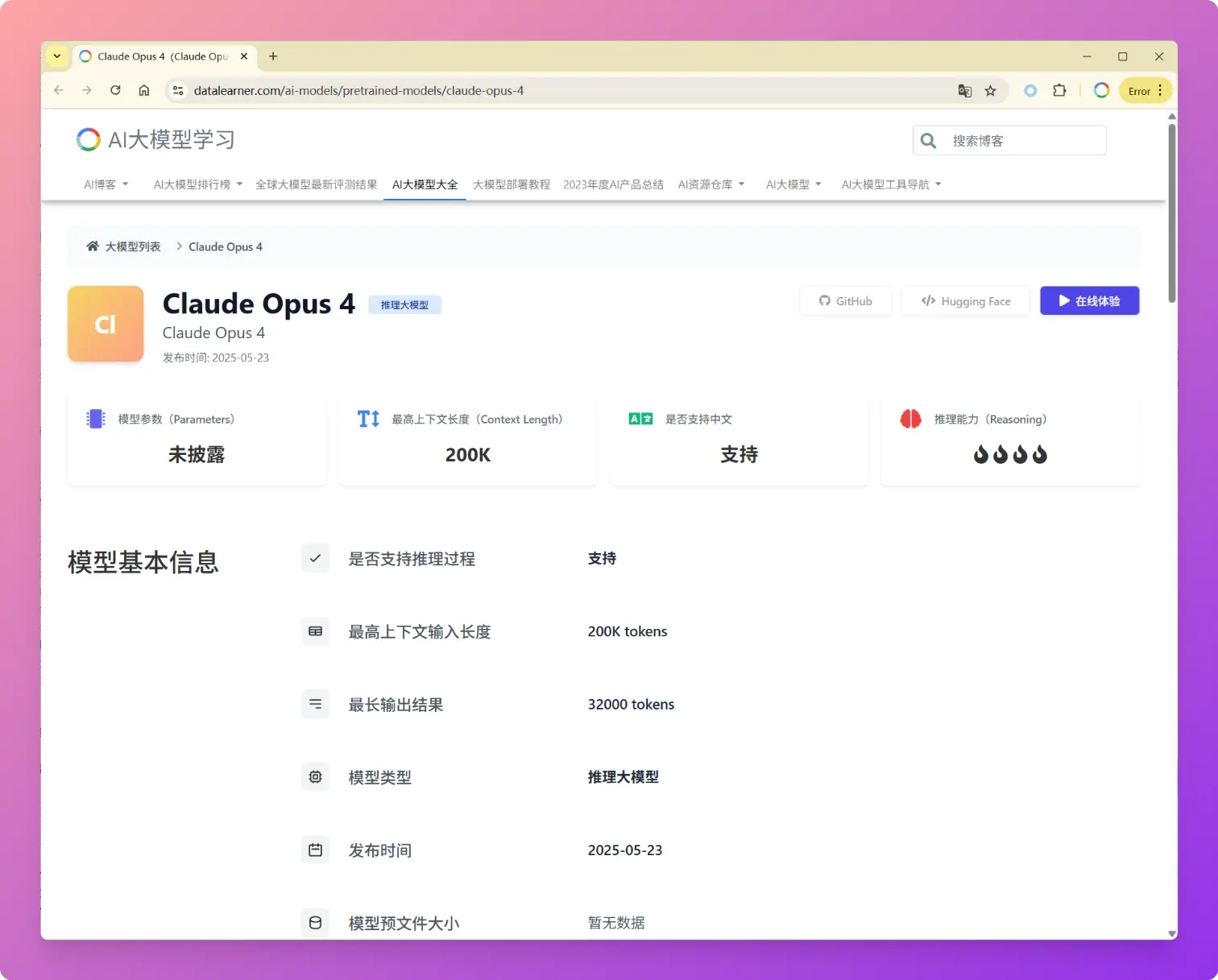
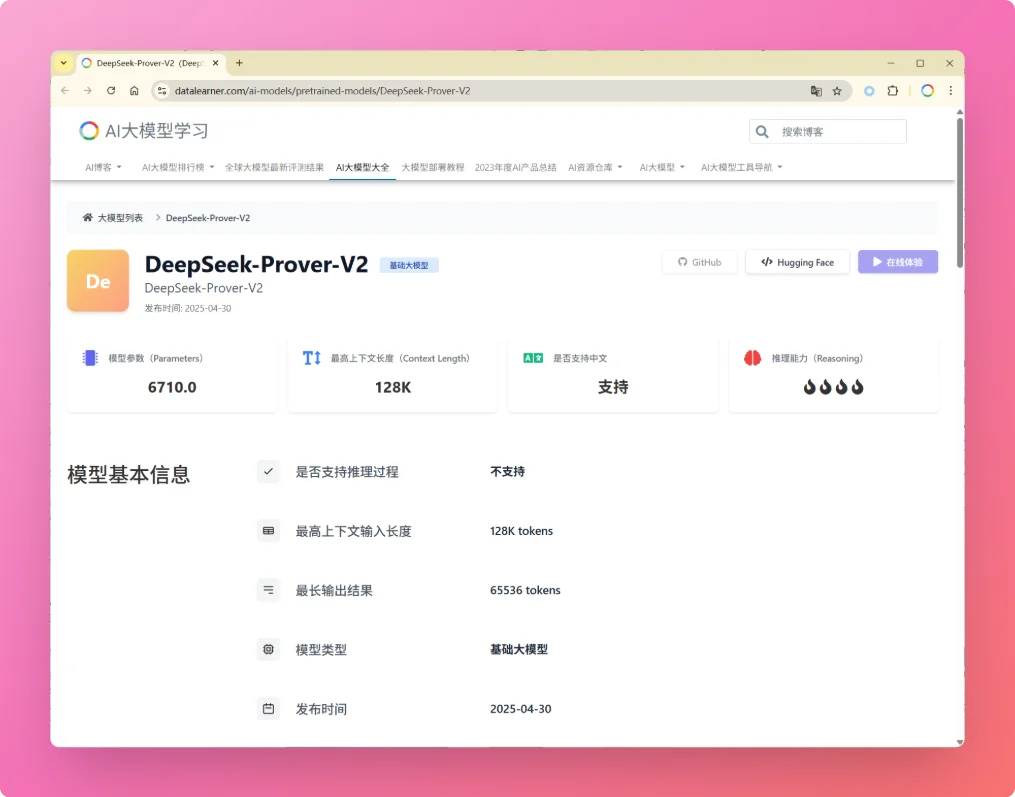
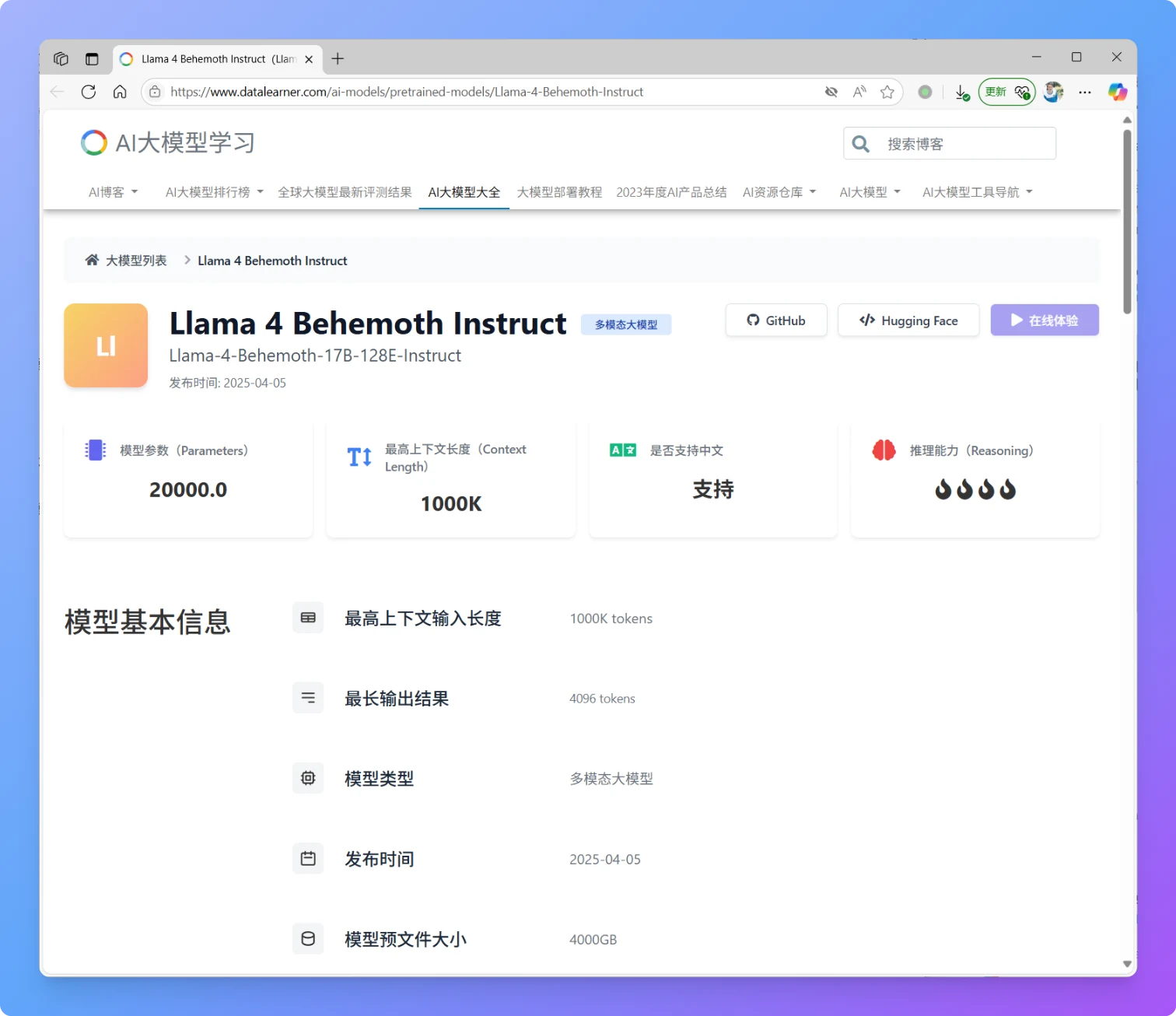
OpenAI发布最强大模型OpenAI o3-pro:业界评价该模型解决复杂问题效果很好,但是回复一句“Hi”也需要三分钟
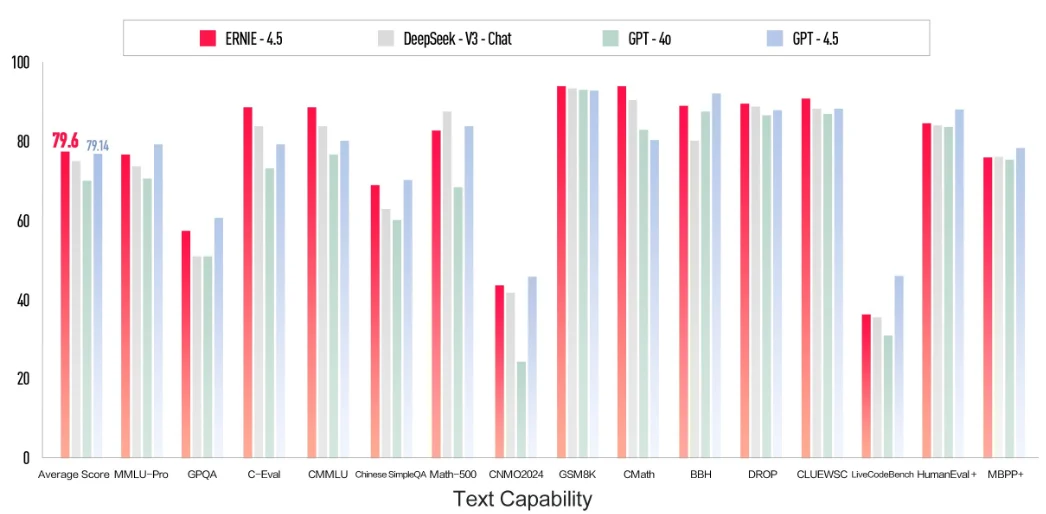
OpenAI 正式发布了其最新模型 OpenAI o3-pro,这是其旗舰模型 o3 的专业增强版。o3-pro 专为需要“更长时间思考”的复杂任务而设计,其核心亮点在于极致的可靠性和准确性,尤其在数学、科学和编程等专业领域表现卓越。根据OpenAI引入的全新“4/4可靠性”评测标准,o3-pro 的性能远超前代,OpenAI官方强调o3-pro在处理高难度、高风险任务的能力上实现了质的飞跃。