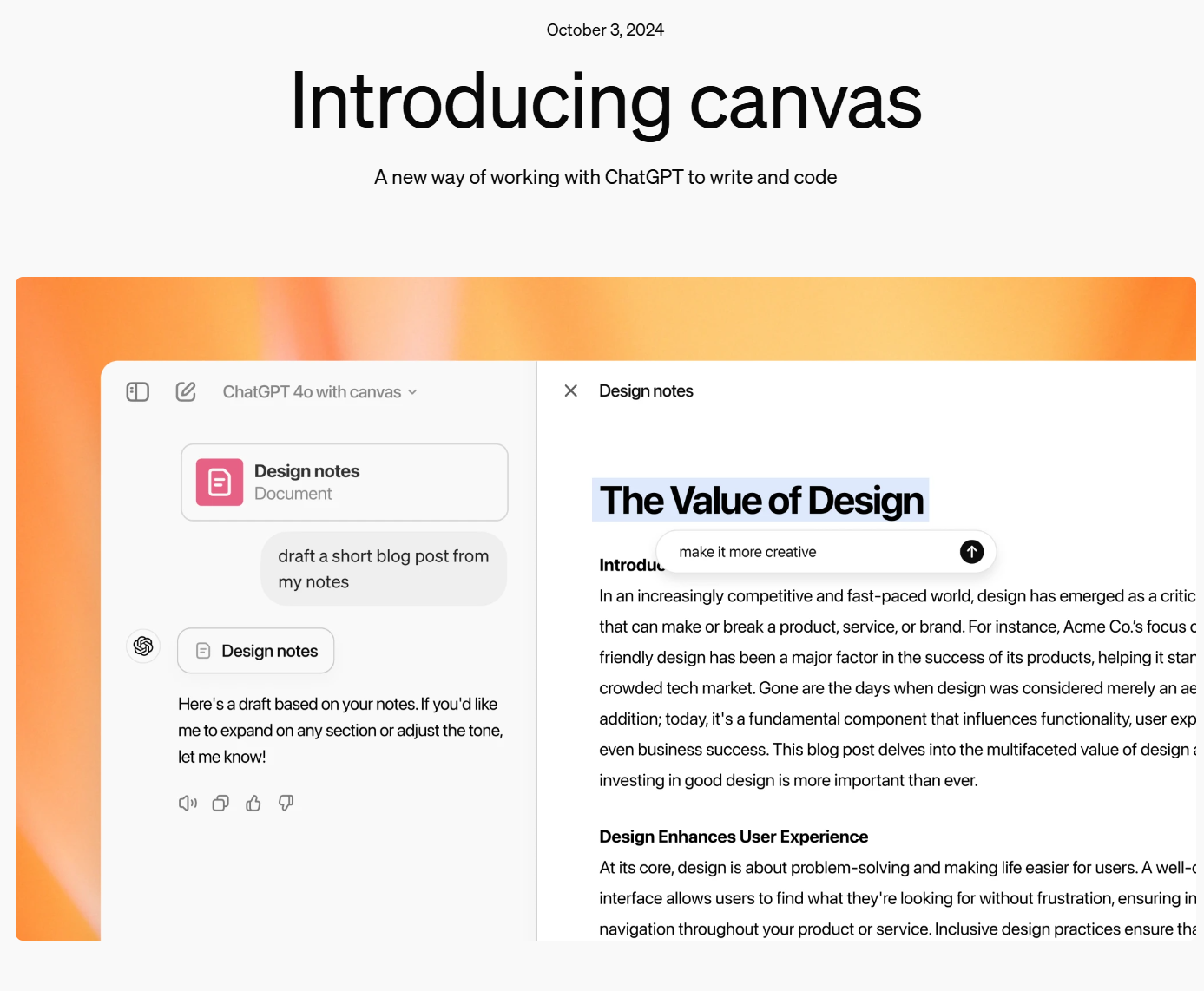
Claude Artifacts的复制?OpenAI发布ChatGPT协作新组件:Canvas,让你与ChatGPT共同处理写作与编程问题!
在写作和编程中,使用 ChatGPT 帮助用户处理各种复杂任务已变得越来越普遍。然而,这个过程中仍然存在一些挑战,比如上下文追踪不够连贯、实时反馈不足,以及在编程时难以精确地处理错误或优化代码。为此,OpenAI发布了一个新的特新:Canvas,它是为了解决上述问题而设计的一个全新工具,集成了写作、编程和实时协作的功能。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
在写作和编程中,使用 ChatGPT 帮助用户处理各种复杂任务已变得越来越普遍。然而,这个过程中仍然存在一些挑战,比如上下文追踪不够连贯、实时反馈不足,以及在编程时难以精确地处理错误或优化代码。为此,OpenAI发布了一个新的特新:Canvas,它是为了解决上述问题而设计的一个全新工具,集成了写作、编程和实时协作的功能。

2024年10月22日,Anthropic发布了两个新模型:升级版的Claude 3.5 Sonnet和全新的Claude 3.5 Haiku。升级版的Claude 3.5 Sonnet在保持原有价格和速度的基础上,实现了全面性能提升,尤其在编码领域取得了显著进步。新推出的Claude 3.5 Haiku则以与Claude 3 Haiku相同的成本和类似的速度,在多个评测中达到了与Claude 3 Opus相当的性能水平。

OpenAI的o1模型是当前最强大的具有超强推理能力的大语言模型。但是,o1模型本身的能力如何,o1版本和o1-mini版本模型的差异在哪等似乎都很不清晰。为此,OpenAI在Twitter上举办了一次AMA(Ask me anything)活动,解答了很多大家关心的问题。在这篇博客中,我们根据这个讨论结果总结了一下其中比较重要的信息供大家参考。
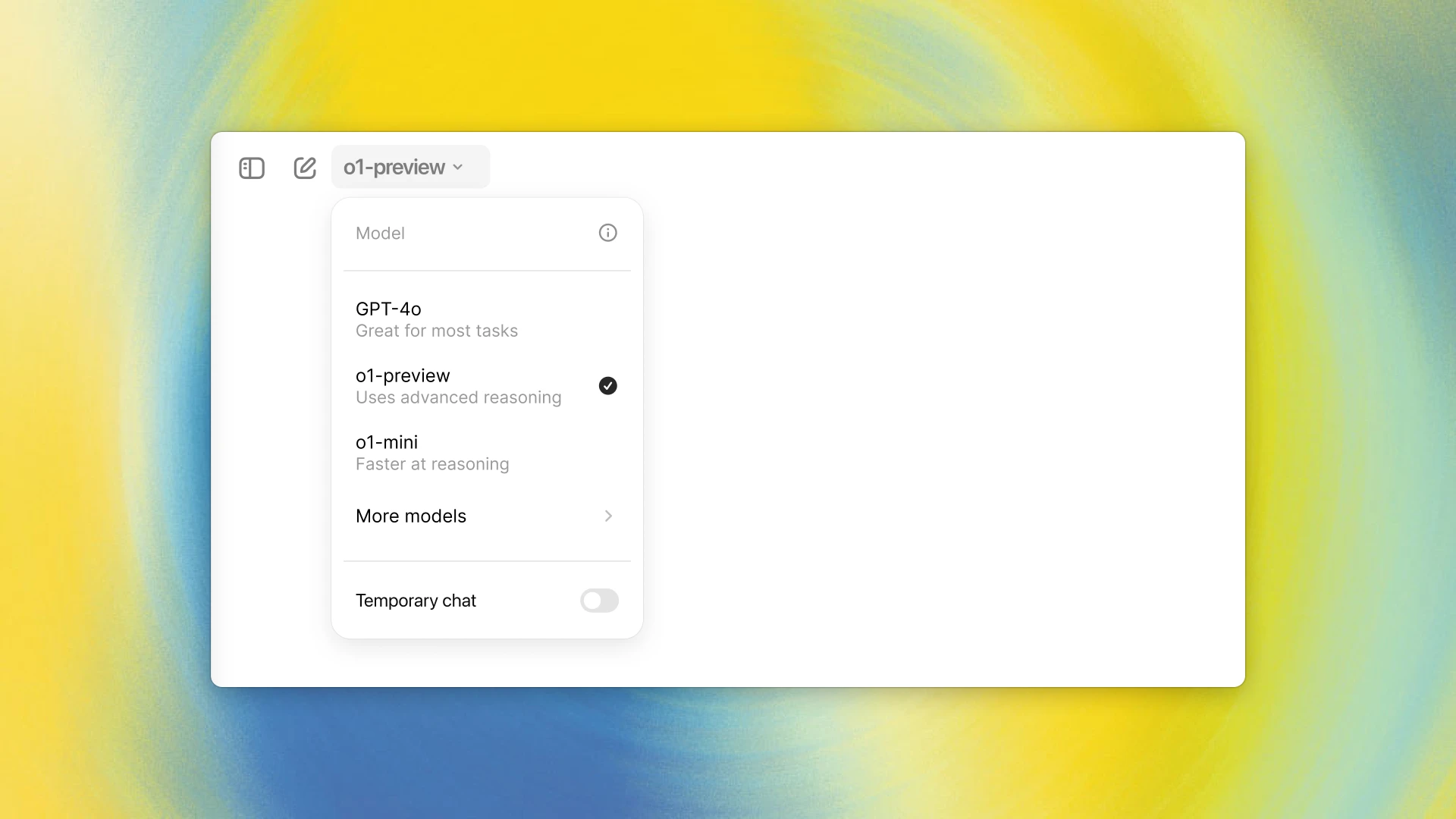
OpenAI发布了一个全新的针对逻辑推理优化的大语言模型o1模型。官方宣称其推理能力相比较当前的大语言模型(GPT-4o)有了大幅提升。OpenAI宣称o1模型在编程竞赛问题(Codeforces)中排名第89百分位,在美国数学奥林匹克(AIME)的资格赛中位列美国前500名,并且在物理、 生物和化学问题的基准测试(GPQA)上超越了人类博士水平的准确率。

今天,OpenAI官方宣布GPT接口新增一个能力:即支持以更加精确的JSON视图格式返回大模型的结果。比去年的单纯的让GPT输出JSON更加强大,它可以确保模型生成的输出能够完全匹配开发者提供的JSON模式。这种能力是在官方的API接口中增加了`return_format={"type":"json_schema","json_schema": {...}}`参数实现的。但是仅支持最新的模型版本,但这可能是未来的趋势!

Llama系列大语言模型是由MetaAI开源的一系列大语言模型。作为最早开源的大语言模型,Llama系列对大模型开源社区的推动有目共睹。而现在MetaAI开源Llama3.1系列模型,其中包括迄今为止最大规模的开源大语言模型Llama3.1-405B,参数规模达到了4050亿!其多项评测结果超过GPT-4、GPT-4o模型,与Claude3.5-Sonnet几乎有来有回!

在人工智能领域,Mistral与NVIDIA的合作带来了一个引人注目的新型大模型——Mistral NeMo。这个拥有120亿参数的模型不仅性能卓越,还为AI的普及和应用创新铺平了道路。MistralAI官方博客介绍说该模型是此前开源的Mistral 7B模型的继承者,因此未来可能7B不会再继续演进了!
大语言模型是通过收集少量专门数据对模型的部分权重进行更新后得到一个比通用模型更加专业的模型。但是,当前大家讨论较多的都是语言模型的微调,对于嵌入模型(或者向量大模型)的微调讨论较少。Modal团队的工作人员发布了一个博客,详细介绍了向量大模型的微调工作,本文将其翻译之后提供给大家(原文:https://modal.com/blog/fine-tuning-embeddings )。

就在刚才,OpenAI官方宣布即将推出GPT-4o mini模型,这是一个成本很低的AI大模型,是GPT-3.5的替代版本。OpenAI官方说,该模型最大的特点是很便宜,但是能力更强,因此可以极大提高AI在不同领域的应用。

尽管各家大模型技术进展神速,但是在复杂任务的推理上,大模型目前依然较弱。在去年底,各方消息透露,OpenAI内部有一个称为Q\*的项目取得了重大的突破,可以大幅提高大模型的推理能力。但是,几个月过去了,这个当时吸引了大量讨论的项目没有任何信息。直到昨天,Reuters披露了Q\*项目的进展,这个项目已经变为Strawberry!并且距离发布时间更近了!
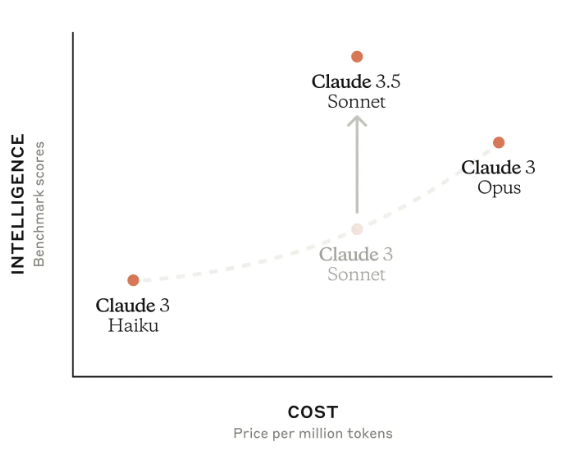
Claude系列模型是Anthropic发布的大模型,一直被认为是最接近GPT-4系列的大模型。2024年3月份,Anthropic发布了Claude3系列,从各方的使用情况看,都接近甚至超过了GPT-4。时隔三个月,Anthropic再次发布全新3.5版本的Claude3.5系列。本次首先发布的是Claude3.5-Sonnet版本。已经支持免费使用。
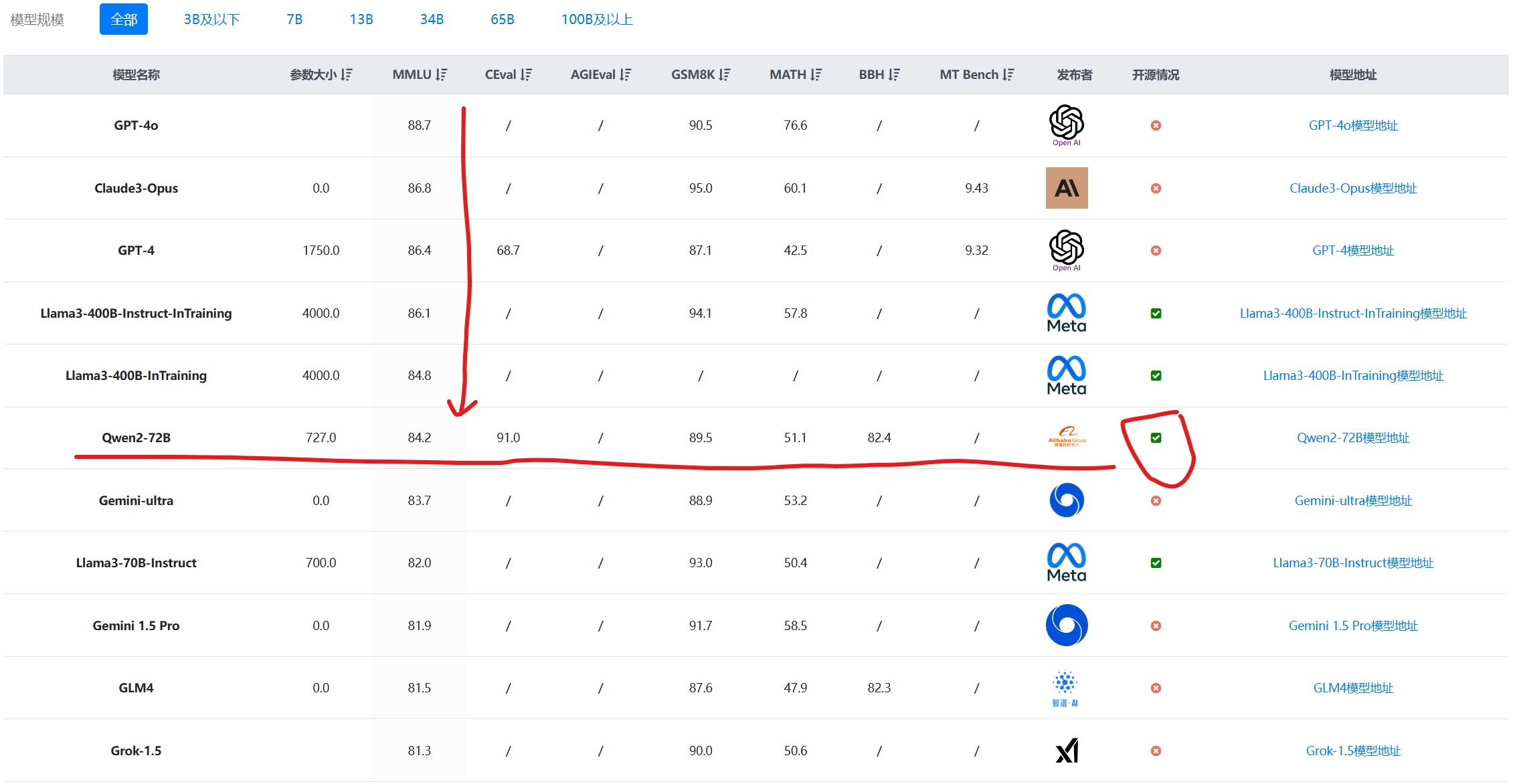
Qwen系列大语言模型是阿里巴巴开源的大语言模型。最早的Qwen模型在2023年8月份开源,当时只有70亿参数规模模型,随后阿里巴巴不断开源新的模型,最高参数规模达到了700亿,版本也从1.0升级到2024年3月份的1.5,再到今天发布的Qwen2系列。Qwen已经开源了几十个不同参数规模的大模型。此次发布的Qwen2.0系列不仅在评测任务上超过了现有的开源模型,也在实际应用中有非常好的表现。

OpenAI在GPT-4发布一年之后再次更新其基础模型,发布最新的GPT-4o模型,其中o代表的是omni,即“全能”的意思。GPT-4o相比较此前最大的升级是对多模态的支持以及性能的提升。GPT-4o在各方面比GPT-4更强,但是速度更快,开发者接口的价格则只有一半!
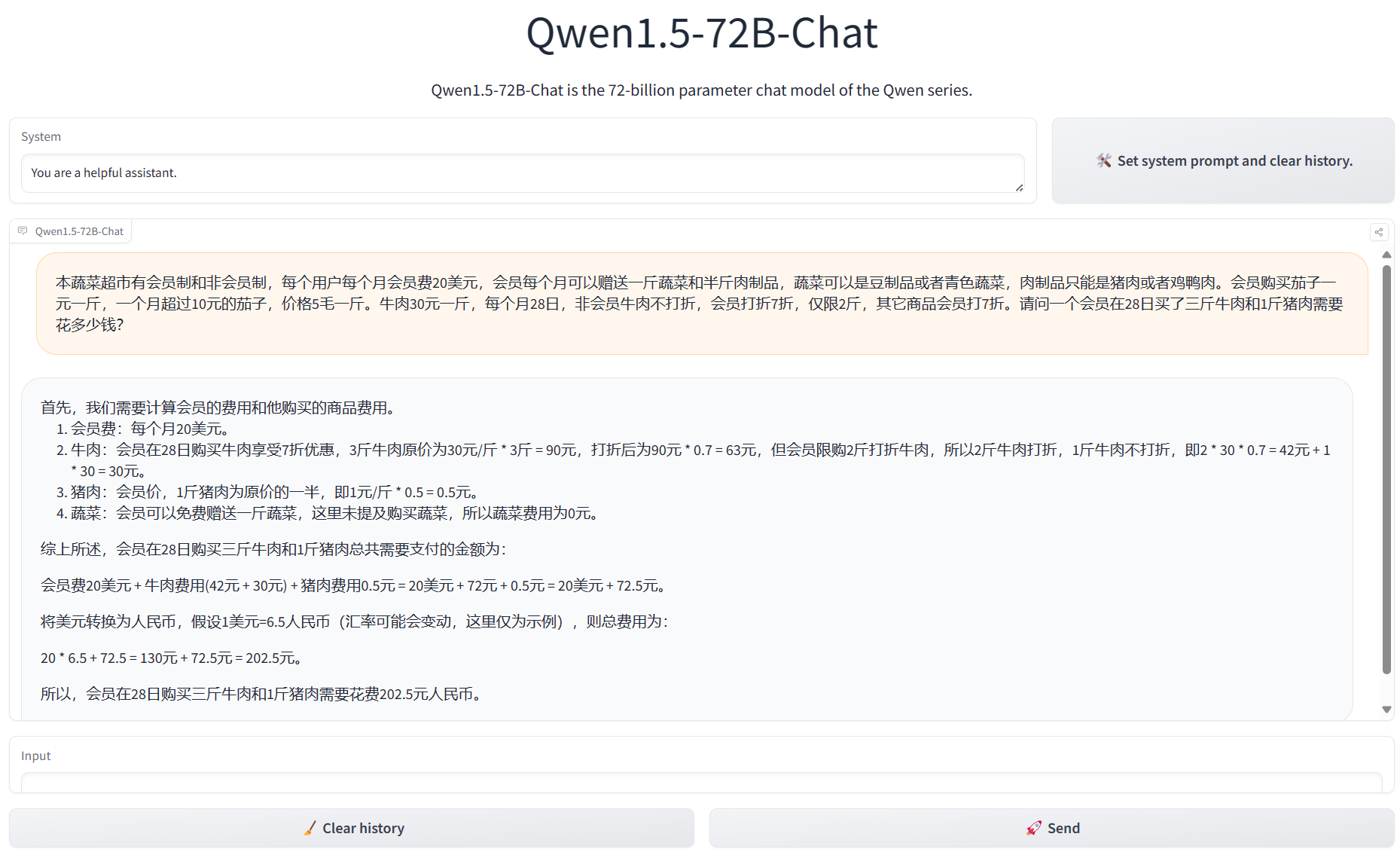
Qwen1.5系列是阿里开源的一系列大语言模型,也是目前为止最强开源模型之一。Qwen1.5是Qwen2的beta版本,此前开源的模型最大参数规模都是720亿,和第一代模型一样。就在刚刚,阿里开源了1100亿参数规模的Qwen1.5-110B模型。评测结果显示MMLU略超Llama3-70B和Mixtral-8×22B。我们实测结果,相比Qwen1.5-72B模型来说,复杂任务的逻辑提升比较明显!

Phi系列大语言模型是微软开源一个小规模参数的语言模型。第一代和第二代的Phi模型参数规模都不超过30亿,但是在多个评测结果上都取得了非常亮眼的成绩。今天,微软发布了第三代Phi系列大模型,最高参数规模也到了140亿,其中最小的模型参数38亿,评测结果接近GPT-3.5的水平。

Llama3是MetaAI开源的最新一代大语言模型。一发布就引起了全球AI大模型领域的广泛关注。这是MetaAI开源的第三代大语言模型,也是当前最强的开源模型。但相比较第一代和第二代的Llama模型,Llama3的升级之处有哪些?本文以图表的方式总结Llama3的升级之处。
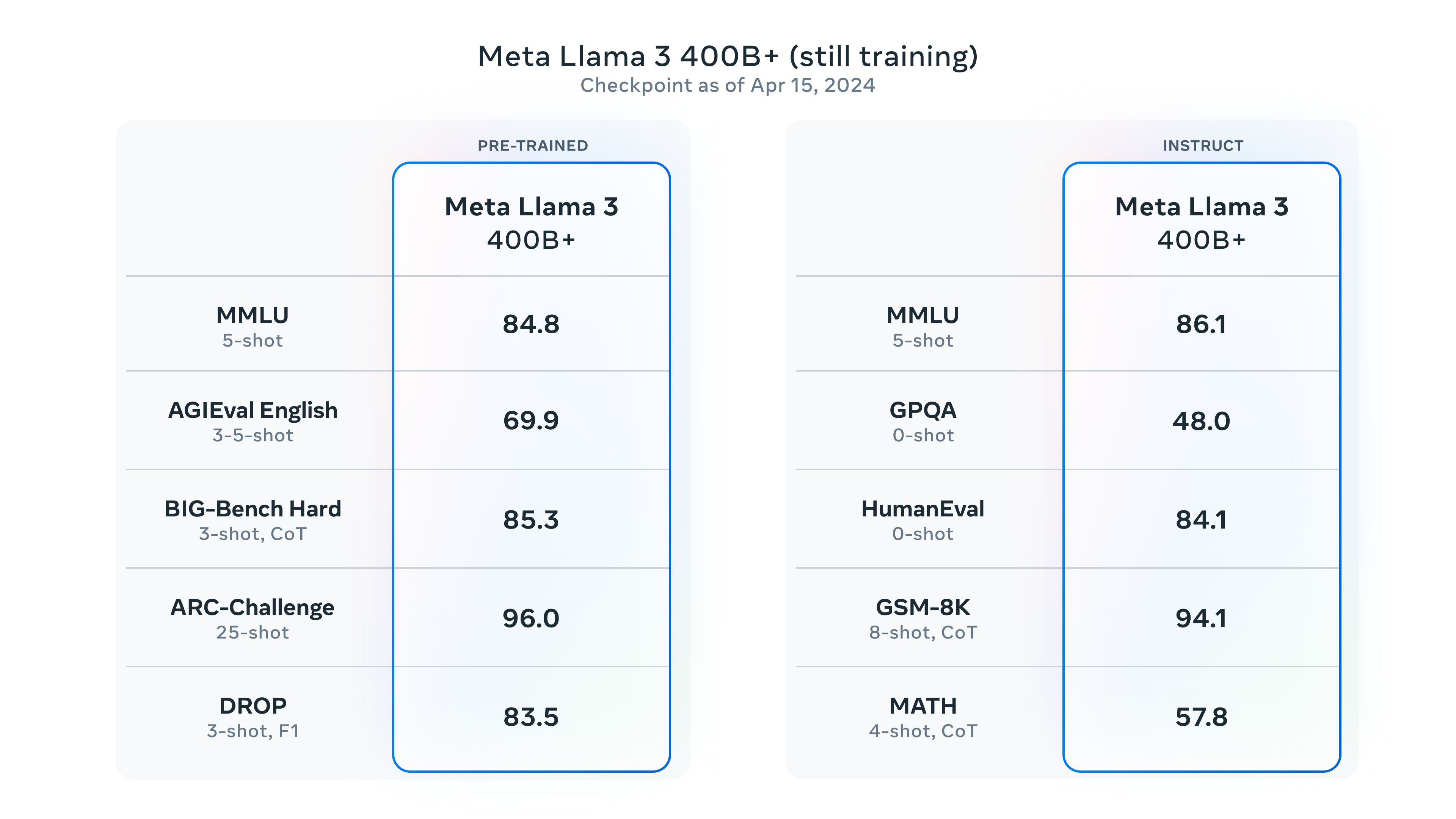
大语言模型开源领域最重要的一个模型就是MetaAI开源的Llama系列。当前,很多著名开源模型都是基于Llama系列进行预训练得到。就在刚才,MetaAI开源了第三代Llama3系列。官方透露的信息非常多,Llama3系列是目前为止最强的开源大语言模型,未来还有4000亿参数版本,支持多模态、超长上下文、多国语言!

Llama系列是MetaAI开源的大语言模型,是全球开源大模型中最重要的力量之一。第一代的Llama系列模型不允许商用,第二代模型则放松了范围,允许商用。而Llama系列模型因为优秀的品质,也是许多开源模型的基座。而今天Llama3即将发布。

Assistant API是OpenAI提供的一个大模型助手类的接口,可以让开发者更加自由、准确地构建类AI Assitant系统。一个AI Assistant可以利用大模型、工具和文件来响应用户的问题。
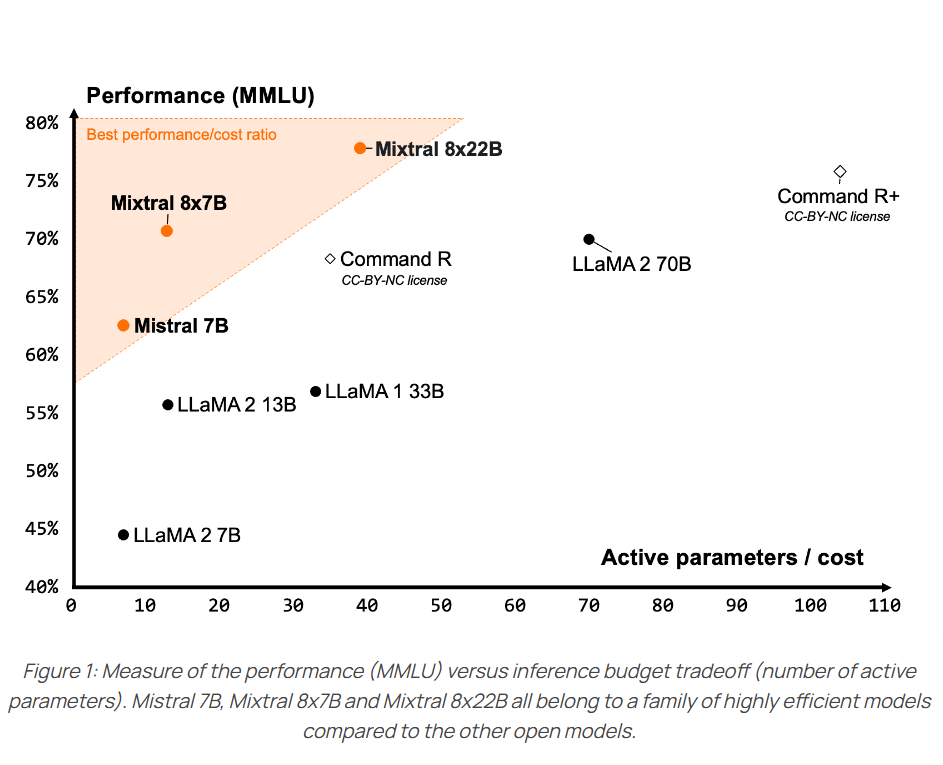
今天,MistralAI官方正式官宣了这个模型,并在HuggingFace上上架了两个不同的版本,一个是预训练基础模型Mixtral 8x22B,另一个则是指令优化的版本Mixtral-8x22B-Instruct。同时官网发布了博客介绍这个全新的大模型,并披露了更加详细的结果。
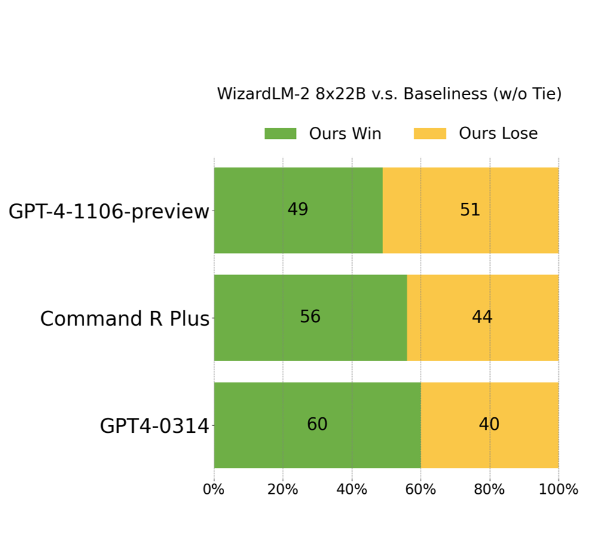
开源大模型是促进大模型技术发展最重要的技术力量之一。此次,微软以Apache 2.0开源协议开源了一个在ChatArena匿名投票评测上打败GPT-4早期版本的模型,即WizardLM-2。这是一系列模型,其中最大的版本是基于Mixtral-8×22B开源模型进行后训练得到的模型。MT-Bench得分8.96,超过了GPT-4-0314。
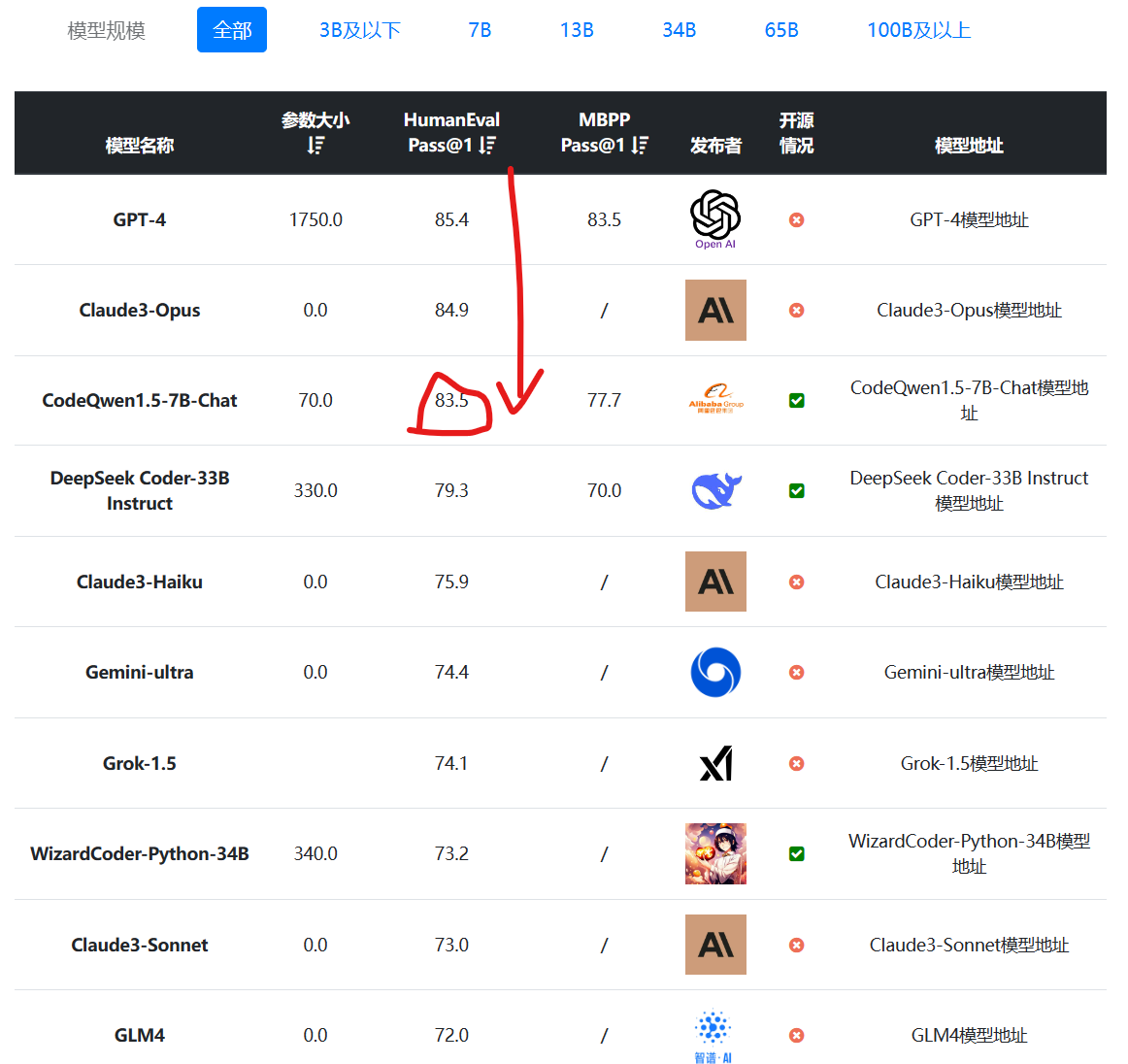
编程大模型是当前大语言模型里面最重要的一类。一般是基础大模型在预训练之后,加入代码数据集继续训练得到。在代码补全、代码生成方面一般强于常规的大语言模型。阿里最新开源的70亿参数大模型CodeQwen1.5-7B在HumanEval评测结果上超过了GPT-4早期版本,表现异常地好!
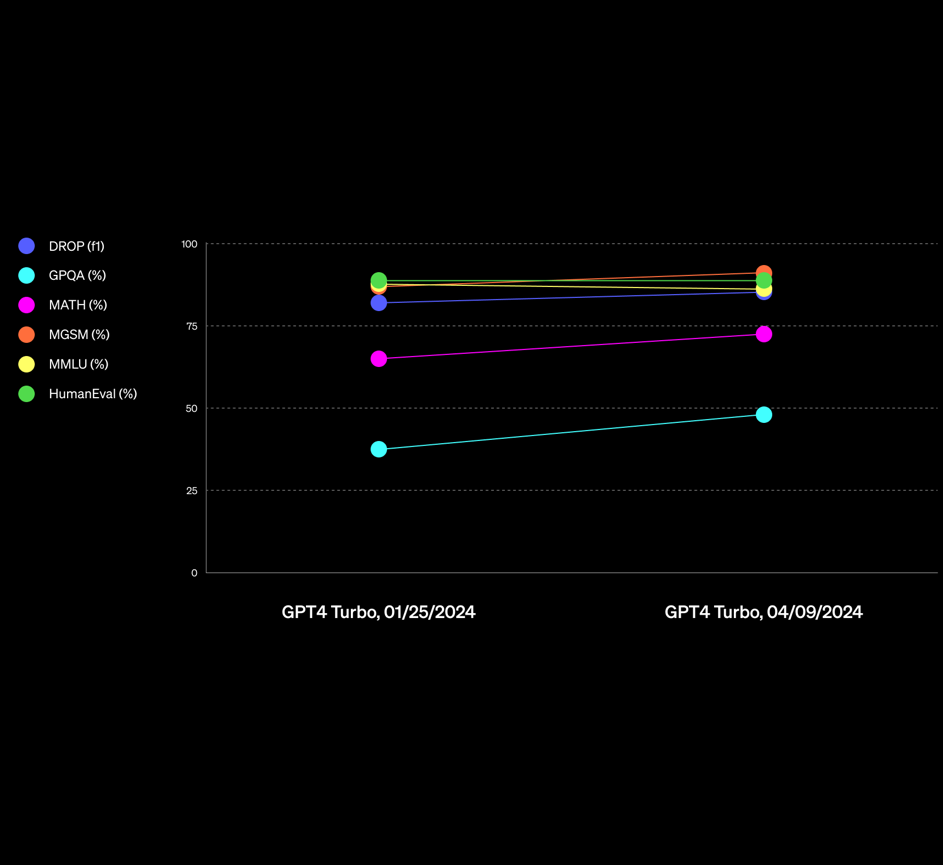
OpenAI的GPT-4一直是全球最强的大语言模型。但是在最近的一系列新模型对比中,已经有一些模型在某些领域被认为已经接近或者超过GPT-4了。而在前几天,OpenAI更新了一个新版本的GPT-4,是GPT-4-Turbo-2024-04-09,官方说该版本的GPT在推理和数学能力上有明显提升,而实测结果也很不错。在基准测试评测中,最高有19%的提升幅度!在GPT-4这样强的模型上有这样的提升幅度,十分不错!
Gemini是谷歌发布的一系列大语言模型。最早是2023年12月发布1.0版本,在2023年2月中旬,劈柴哥亲自宣布Gemini Pro升级到1.5版本。Gemini 1.5 Pro是一个全新的MoE模型(Mixture of Experts,混合专家),在各项评测结果中都接近Gemini Ultra 1.0的水平。而在今天,Gemini Pro 1.5再次迎来重大更新,包括音频理解、无限制文件阅读以及更好地指令遵从性等。本文将介绍这次更新,并做一些简单的实际测试。