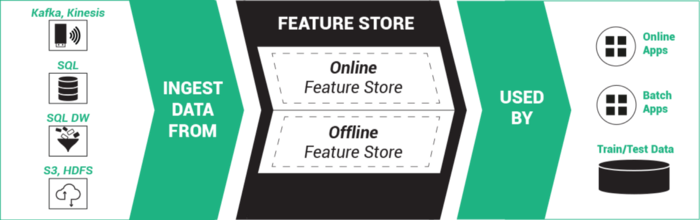
亚马逊最新发布Feature Store简介
在2020年的亚马逊reInvent发布会上,亚马逊正式发布了一项新的服务,即Amazon SageMaker Feature Store,中文简介是适用于机器学习特征的完全托管的存储库。 Feature Store是这两年兴起的另一个关于人工智能系统的基础设施,应该也是未来几年最重要的人工智能基础设施之一。本文将介绍一下Feature Store是什么以及为什么很多企业开始推广这个东西。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
在2020年的亚马逊reInvent发布会上,亚马逊正式发布了一项新的服务,即Amazon SageMaker Feature Store,中文简介是适用于机器学习特征的完全托管的存储库。 Feature Store是这两年兴起的另一个关于人工智能系统的基础设施,应该也是未来几年最重要的人工智能基础设施之一。本文将介绍一下Feature Store是什么以及为什么很多企业开始推广这个东西。

运行本地dask集群的时候出错Task exception was never retrieved的解决方法

有的时候使用Python遇到内存溢出的问题,但其实机器剩余内存很多。需要注意Python版本是否正确

SCI期刊可能是国内科研活动中与期刊最相关的话题内容。类似的,包括SCIE、SSCI和EI期刊也是常见的话题。本文将对这几个名词进行解释,并着重说明SCIE是否属于SCI、以及SCI和EI、SSCI的区别。
为学术新人提供的学术工具列表
新浪博客转入

NumPy是Python中非常优秀的一个数据科学工具包,使用Python做数据分析的童鞋几乎是必备的工具。NumPy的提供了非常丰富的计算能力,但是底层是C语言实现的,因此既有Python语法的低门槛,速度上却依然非常好。NumPy本身也和Pandas、SciPy一起成为一种生态了。今天,NumPy发布了1.20.0最新版本,这个版本的改动很大。值得童鞋们关注~
123123
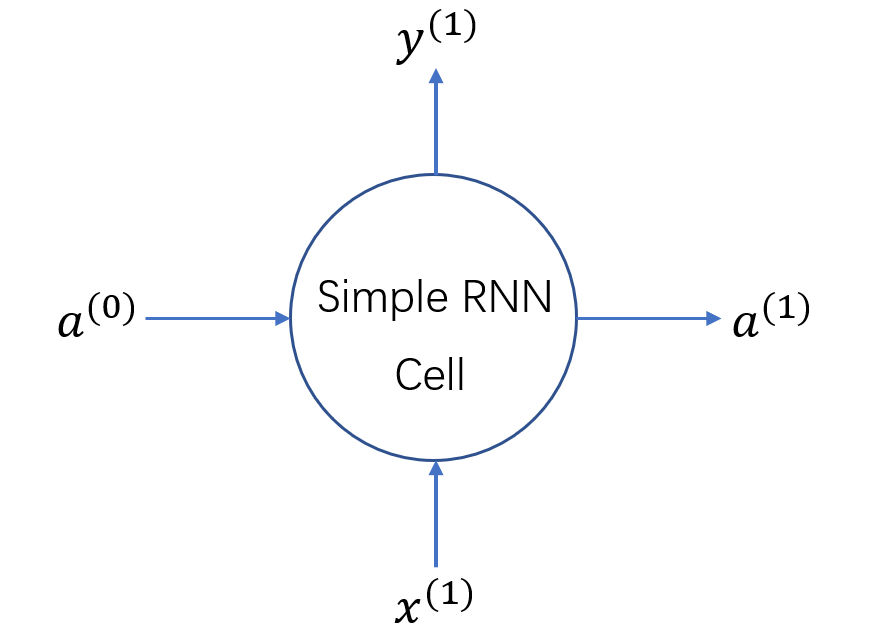
RNN的应用有很多,尤其是两个RNN组成的Seq2Seq结构,在时序预测、自然语言处理等方面有很大的用处,而每个RNN中一个节点是一个Cell,它是RNN中的基本结构。本文从如何使用RNN建模数据开始,重点解释RNN中Cell的结构,以及Keras中Cell相关的输入输出及其维度。我已经尽量解释了每个变量,但可能也有忽略,因此可能对RNN之前有一定了解的人会更友好,本文最主要的目的是描述Keras中RNNcell的参数以及输入输出的两个注意点。如有问题也欢迎指出,我会进行修改。
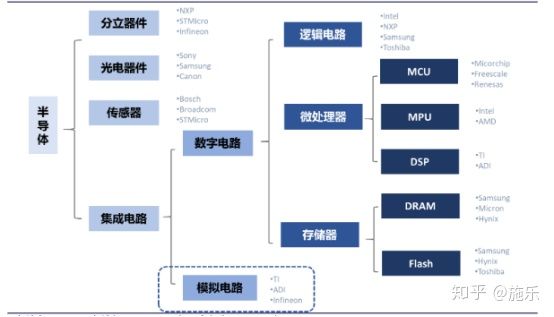
美国对华为的制裁让我们看到半导体领域核心技术国产化的重要性,尽管国内互联网发展迅速,也产生了阿里、腾讯、美团等巨头,但是底层的硬件技术依然依赖于西方国家。其实我个人觉得也不是我们多么希望自己自力更生,实在是被逼无奈,时不时断供一下,这谁能受得了。最近个人也在补充这些知识,把一些学习的这些东西记录下来,如有问题也希望大家指出。
网站启用HTTPS必须制作证书,而证书的制作需要定期更新。这里介绍了Certbot证书自动生成工具和自动更新的方法。并描述了Tomcat如何配置pem证书。
在使用Dask进行两个dataframe的concatenate操作的时候抛出ValueError,本文记录这个错误以及解决方案。
TEST
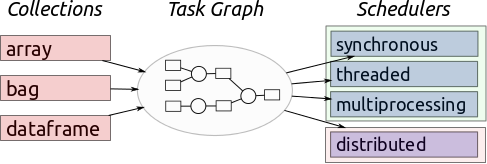
Dask支持多种调度器,从单线程、多线程、多进程到本地分布式和集群分布式,各种调度器在不同情况下有不同的作用,本文来源于Dask官方文档的翻译,主要向大家介绍这五种调度器的使用情景和方式。最后提供了如何在不同情境下设置Dask调度器的方法。
在前面的博客中,我们已经对`Dask`做了一点简单的介绍了,在这篇博客中我们来对比一下`Dask`的`DataFrame`在不同条件下的运算性能,主要是连接操作的性能(merge)。
使用Dask进行分布式处理的时候一个最常见的场景是有很多个文件,每个文件由一个进程处理。这种操作经常会遇到一个程序挂起的问题,使得程序永远运行,无法结束。本文描述如何解决。
使用pandas的DataFrame和dask的DataFrame保存数据到csv文件时候会出现两个换行符的情况。本文描述如何解决。
Dask的集群启动创建也很简单,有好几种方式,最简单的是采用官方提供dask-scheduler和dask-worker命令行方式。本文描述如何使用命令行方法建立Dask集群。
当数据量达到一定程度,单机的处理能力会无法达到性能的要求,采用并行计算,并利用多台服务器进行分布式处理可能会提升数据处理的速度,达到性能要求。然而如果使用不当,并行处理可能并不会提升处理的速度。这篇博客介绍了Dask中关于并行处理的一些效率方面的建议,尽管是针对Dask的说明,但对于所有的并行处理来说都是适用的。
Dask提供了多种分布式调度器,当缺少多台服务器时候,也可以通过本地集群来实现单机分布式的计算。这篇博客主要就是介绍如何实现Dask的单机分布式调度器。第一小节是简介,第二节是单机调度器的简写版本,第三节是单机调度器的完整版本,第四节是使用的一些示例。
221
Pandas中的DataFrame选择某些行和某些列是有很多中操作和选择的,不太容易记,这里整理一下。
Git操作记录