
最高50万美金!全新高额奖金的AI竞赛——AI预测大赛
预测在全球决策中发挥着关键作用。例如,关于COVID-19扩散的预测为国家封锁提供了信息,而经济预测则影响了利率的制定。这些预测通常依赖于人类专家的仔细判断,他们必须考虑来自各种来源的数据。由于人工智能系统能够处理大量的数据,它们在这个领域有可能非常有用。 为此,ML Safety举办了一个关于AI预测的竞赛,比赛的目的是建立一个机器学习模型,做出准确和校准的预测。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
预测在全球决策中发挥着关键作用。例如,关于COVID-19扩散的预测为国家封锁提供了信息,而经济预测则影响了利率的制定。这些预测通常依赖于人类专家的仔细判断,他们必须考虑来自各种来源的数据。由于人工智能系统能够处理大量的数据,它们在这个领域有可能非常有用。 为此,ML Safety举办了一个关于AI预测的竞赛,比赛的目的是建立一个机器学习模型,做出准确和校准的预测。
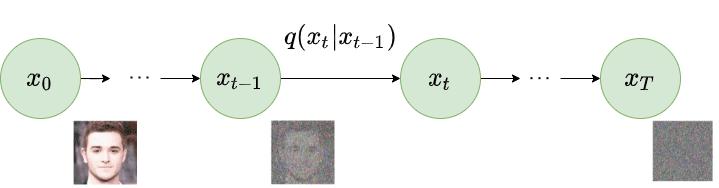
随着DALL·E2的发布,大家发现Text-to-Image居然可以取得如此好的效果。也让diffusion模型变得非常受欢迎。扩散模型虽然火热,但是背后的数学原理可能很多人也不太了解。这篇博客不仅介绍了扩散模型背后的数学原理,也讲述了如何训练扩散模型以及提高扩散模型训练效率的种种技巧,十分值得大家钻研。
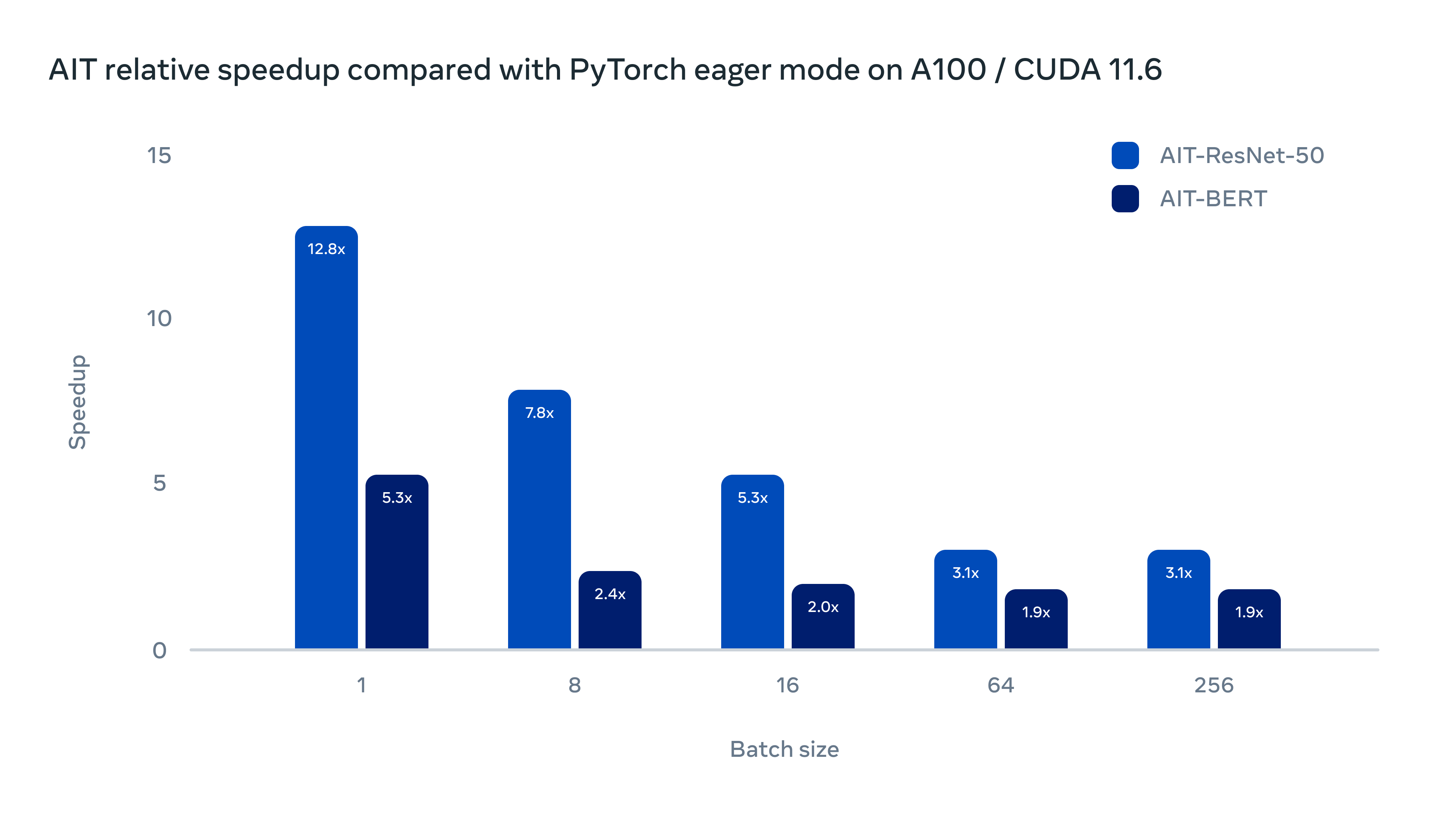
为了提高AI模型的推理速度,降低在不同GPU硬件部署的成本,Meta AI研究人员在昨天发布了一个全新的AI推理引擎AITemplate(AIT),该引擎是一个Python框架,它在各种广泛使用的人工智能模型(如卷积神经网络、变换器和扩散器)上提供接近硬件原生的Tensor Core(英伟达GPU)和Matrix Core(AMD GPU)性能。

九月份刚过去,GitHub上最火的AI研究排序出炉。这是根据9月份GitHub上创建的新的AI研究相关的项目排序,根据Star的数量来的。都是AI各大领域比较受欢迎和重要的项目。

随着NLP预训练模型的发展,大语言模型在各个领域的作用也越来越大。几个月前,GitHub基于OpenAI的GPT-3训练的Copilot效果十分惊艳,可惜现在已经开始收费。而最近,清华大学也发布了一个代码补全神器——CodeGeeX。
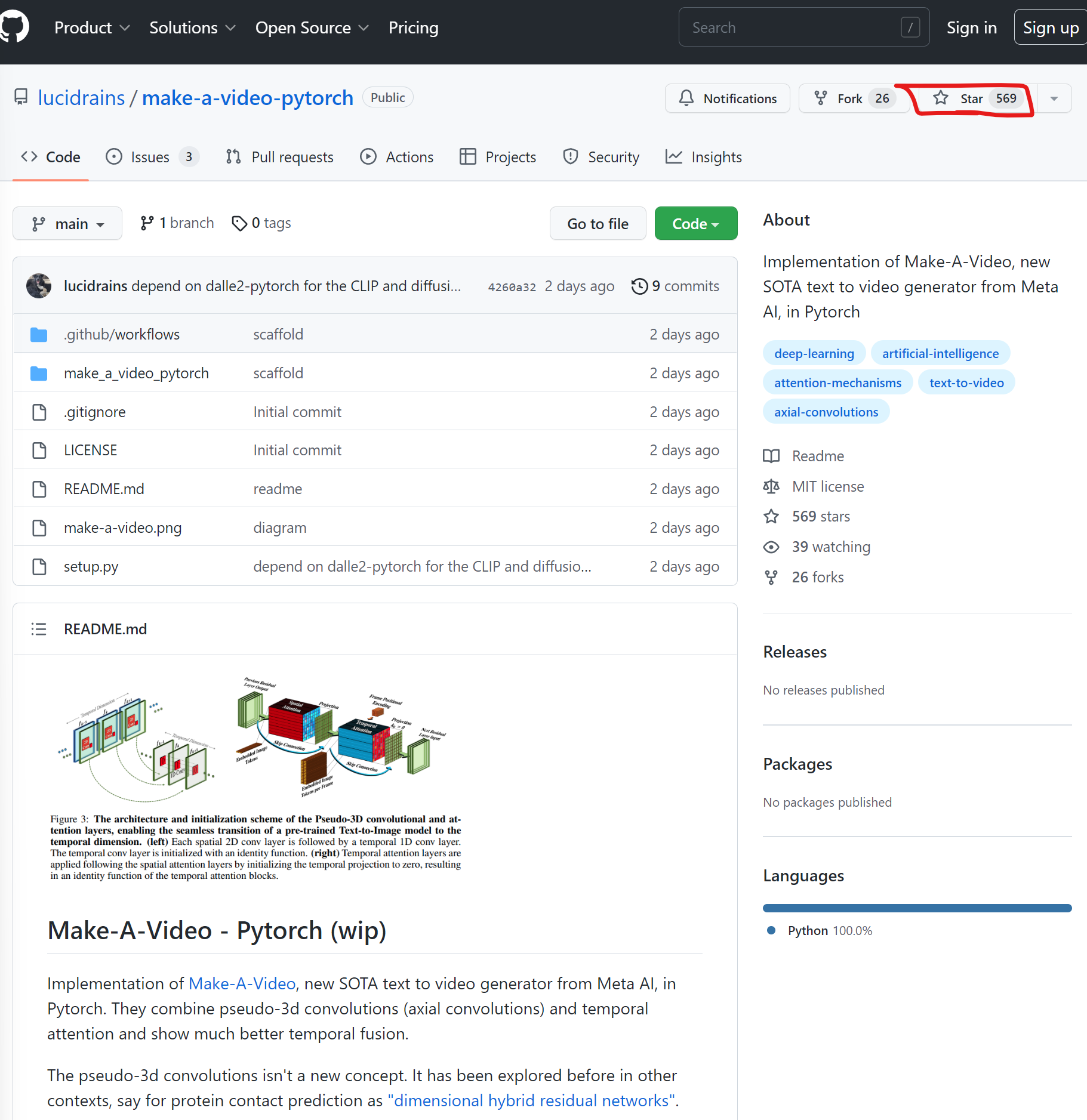
MetaAI在2天前刚发布了一个最新的Text-to-Video模型,让生成模型从逼真的图片生成往前推进到视频生成。当然,官方还是希望将其当作一种SaaS服务提供。但是,才2天,业界基于论文的开源PyTorch实现就已经准备公开,且获得了569个Star!卷到家了!
DALLE·2的出现,让大家认识到原来文本生成图片可以做到如此逼真效果,此后Stable Diffusion的开源也让大家把Text-to-Image玩出花了。而现在,Meta AI的研究人员让这个工作继续往前一步,发布了Text-to-Video的预训练模型:Make-A-Video。

Stable Diffusion是一种功能强大的开源文本到图像(Text-to-Image)生成模型。虽然目前有多个开源项目可以实现基于文本提示(prompt)创建图像,但Stable Diffusion性能极其强大,其结果甚至可以媲美DALL·E2。而现在KerasCV提供了这个模型的官方实现!
KerasCV是由Keras官方团队发布的一个计算机视觉框架,可以帮助大家用来处理计算机视觉领域的相关任务和问题。这是2022年4月刚发布的最新产品,由于是官方团队出品的工具,所以质量有保证,且社区活跃,一直在积极更新。
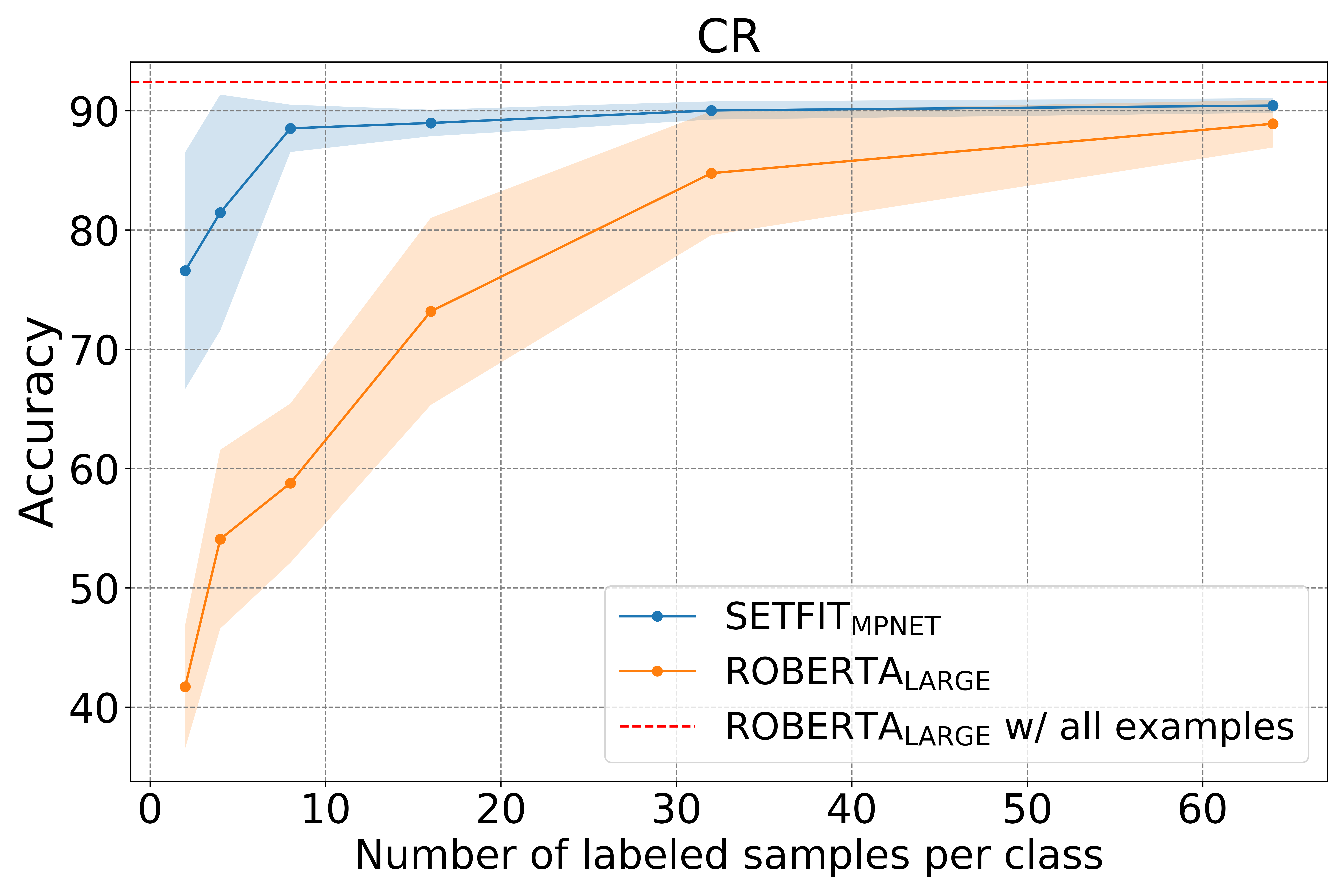
少量标记的学习(Few-shot learning)是一种在较少标注数据集中进行模型训练的一种学习方法。为了解决大量标注数据难以获取的情况,利用预训练模型,在少量标记的数据中进行微调是一种新的帮助我们进行模型训练的方法。而就在昨天,Hugging Face发布了一个新的语句transformers(Sentence Transformers)框架,可以针对少量标记数据进行模型微调以获取很好的效果。

马尔可夫链(Markov Chain)是由马尔可夫性质推导出来的一种重要的概率模型。马尔科夫链是一种离散时间的随机过程,作为现实世界的统计模型,有很多应用。在热力学、统计力学、排队理论、金融领域等都有重要的应用价值。 作为一种离散时间的随机过程,与其对应的模型是马尔可夫过程(Markov Process),这是一种连续时间随机过程的模型。本节将主要介绍马尔科夫链。
Salesforce的研究人员开发了LAVIS(LAnguage-VISION的缩写),这是一个开源的库,用于在丰富的常见任务和数据集系列上训练和评估最先进的语言-视觉模型,并用于在定制的语言-视觉数据上进行现成的推理。
最近,谷歌发布了一项新的工具:Google Interview Warmup,让你练习回答由行业专家选定的问题,并使用机器学习来转录你的答案,帮助你发现改进面试的回答。
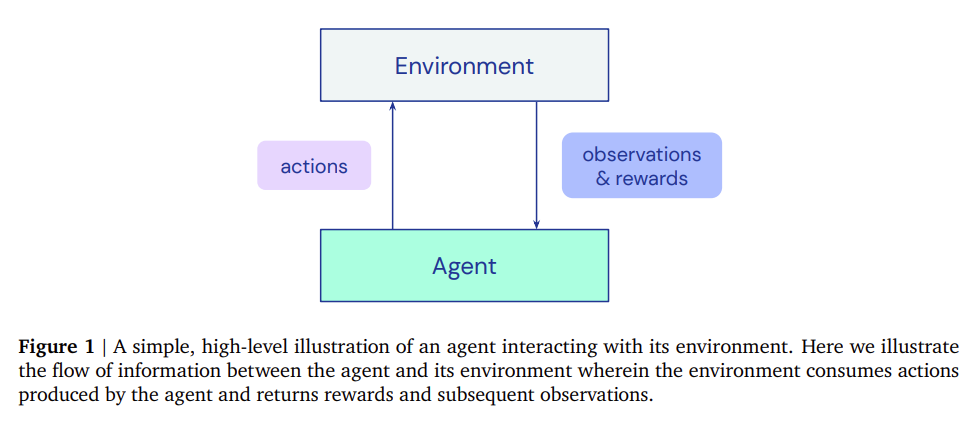
深度强化学习(RL)导致了许多最近的和突破性的进展。然而,强化学习的实施并不容易,与使深度学习拥有PyTorch这样简单的框架支持不同,强化学习的训练缺少强有力的工具支撑。为了解决这些问题,DeepMind发布了Acme,一个用于构建新的RL算法的框架,该框架是专门为实现代理而设计的

今天Google发布了TensorStore,这是一个开源的C++和Python软件库,设计用于存储和操作大规模n维数据。TensorStore已经被用来解决科学计算中的关键工程挑战(例如,管理和处理神经科学中的大型数据集,如石油级的三维电子显微镜数据和神经元活动的 "4d "视频)。TensorStore还被用于创建大规模的机器学习模型,如PaLM,解决了分布式训练期间管理模型参数(检查点)的问题。

Stable Diffusion是最近很火的Text-to-Image预训练模型(详细信息:https://www.datalearner.com/ai-resources/pretrained-models/stable-diffusion )。而现在,相关的视频教程已经出现。fast.ai的团队宣布了一门新的深度学习课程《From Deep Learning Foundations to Stable Diffusion》上线!
最近一段时间Text-to-Image模型十分火热。OpenAI的DALL·E2模型的效果十分惊艳。不过,由于Open AI现在的不Open策略,大家还无法使用这个模型,业界只开放了一个小版本的DALL·E mini。不过,前段时间,Stability AI发布的Stable Diffusion其效果明显好于现有模型,且免费开放使用,让大家都开心了一把。不过原有模型是Torch实现的,而现在,基于Tensorflow/Keras实现的Stable Diffusion已经开源。

LAION全称Large-scale Artificial Intelligence Open Network,是一家非营利组织,成员来自世界各地,旨在向公众提供大规模机器学习模型、数据集和相关代码。他们声称自己是真正的Open AI,100%非盈利且100%Free。在九月份,他们公布了一个全新的图像-文本对(image-text pair)数据集。该数据集包含4亿条数据。
昨天,Meta的Zuckerberg宣布,将PyTorch由Meta AI移交给Linux Foundation托管。这意味着PyTorch从今天起从Meta独立,并作为Linux Foundation下的一个项目。
强化学习(Reinforcement Learning)是近年来十分火热的一种机器学习研究领域。随着DeepMind(谷歌旗下的研究机构)的AlphaGo在围棋界战胜人类之后,这类方法开始被人们广泛关注。但是,强化学习并不是突然出现,也不是DeepMind的首创,在很久之前,这种方法已经开始发展,但是近年来,随着AI相关的软硬件能力的提升,强化学习的实用价值也开始显现。本文不涉及强化学习本身的技术细节,仅仅记录这种方法的历史由来。

随着安全隐私被大家所重视,网站开启HTTPS访问已经是不可阻挡的趋势。HTTPS协议就是借助SSL/TLS证书实现http的加密传输的协议(HTTP Over SSL/TLS)。本文将记录如何使用第三方库申请Let's Encrypt证书,并在tomcat中开启相关的功能。
原来直接用root账户授权远程访问失败,最新的MySQL8不允许直接创建并授权用户远程访问权限,必须先让自己有GRANT权限,然后创建用户,再授权。
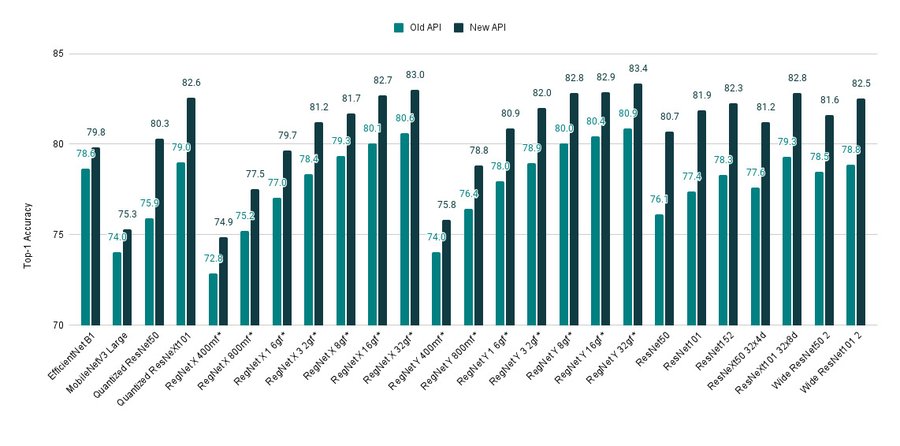
PyTorch最新的1.12版本已经在前天发布。而其中TorchVision是基于PyTorch框架开发的面向CV解决方案的一个PyThon库,其最主要的特点是包含了很多流行的数据集、模型架构以及预训练模型等。本次也随着PyTorch1.12的发布更新到了v0.13。此次发布包含几个非常好的提升,值得大家关注。
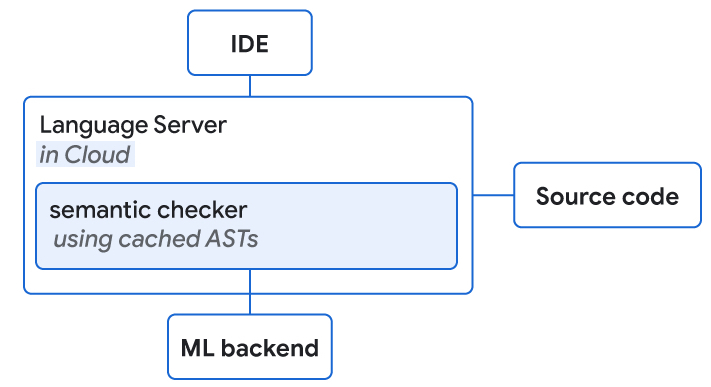
我们将介绍如何将ML和SE结合起来,开发一种新的基于Transformer的混合语义ML代码补全,现在可供内部谷歌开发人员使用。我们讨论了如何通过(1)使用ML对SE单标记建议重新排序,(2)使用ML应用单行和多行补全并使用SE检查正确性,或(3)使用单标记语义建议的ML的单行和多行延拓来组合ML和SE。