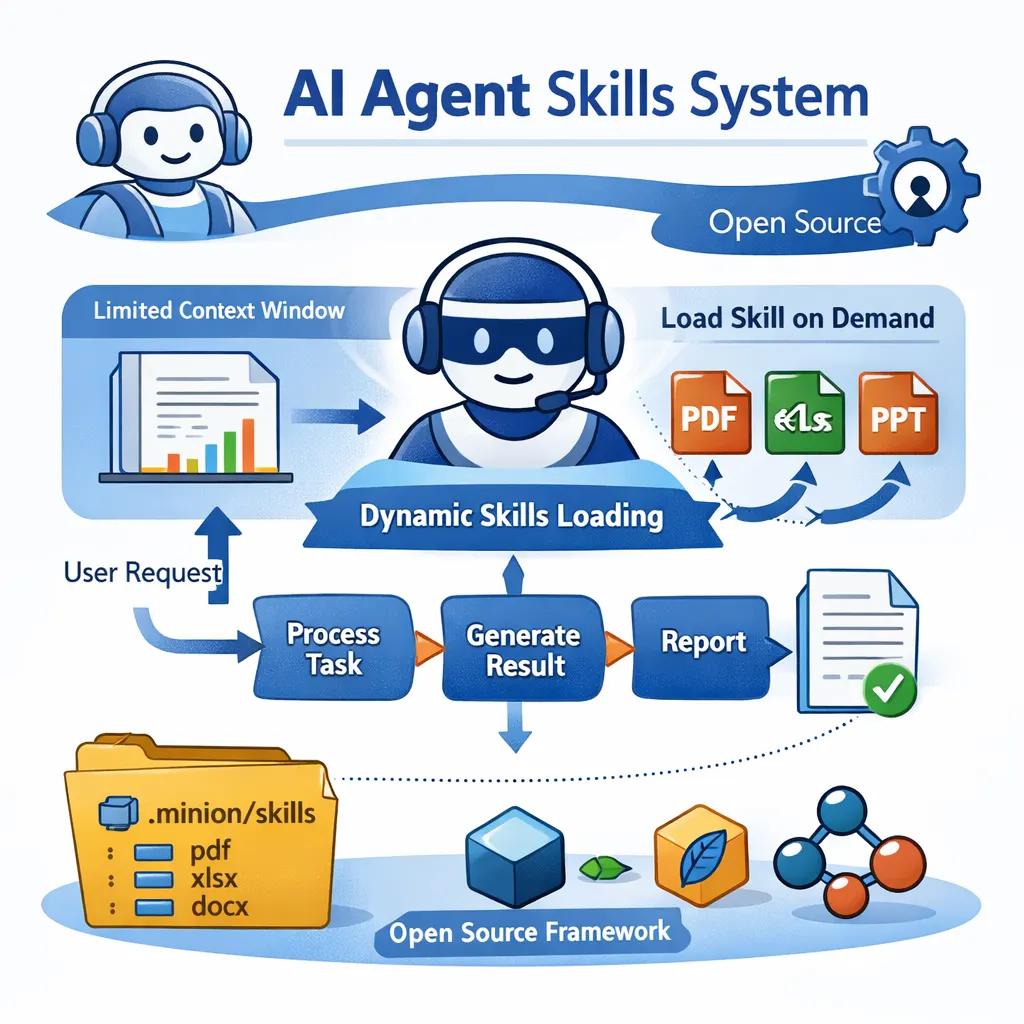
Minion Skills: Claude Skills的开源实现
本文介绍了 Claude 最近推出的 Skills 系统,以及作者在 Minion 框架中实现的一个完全开源的版本。Skills 的核心思路是让 AI Agent 在需要时再加载对应的专业能力,而不是一开始就把所有工具和知识都塞进上下文,从而缓解上下文窗口有限、成本高、响应慢的问题。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
本文介绍了 Claude 最近推出的 Skills 系统,以及作者在 Minion 框架中实现的一个完全开源的版本。Skills 的核心思路是让 AI Agent 在需要时再加载对应的专业能力,而不是一开始就把所有工具和知识都塞进上下文,从而缓解上下文窗口有限、成本高、响应慢的问题。

OpenAI 刚刚把 GPT-5.2 推上来了。我们在 DataLearnerAI 上把它和 Claude Opus 4.5、Gemini 3.0 Pro(Preview) 放到同一个对比页里,拉齐公开评测与基础规格,做一个“站在真实选择角度”的快速判断。

2025年11月24日,Anthropic正式发布了Programmatic Tool Calling (PTC)特性,允许Claude通过代码而非单次API调用来编排工具执行。这一创新被认为是Agent开发的重要突破,能够显著降低token消耗、减少延迟并提升准确性。 然而,作为minion框架的创建者,我想分享一个有趣的事实:minion从一开始就采用了这种架构理念。在PTC概念被正式提出之前,minion已经在生产环境中证明了这种方法的价值。

就在刚才,智谱推出了两个语音识别模型:闭源的 GLM-ASR 和开源的 GLM-ASR-Nano-2512。与过去他们更多关注通用大模型或多模态模型不同,这次聚焦的是语音转文字(ASR)任务,尤其面向中文语境、方言与复杂环境。以下是对这两款模型已知公开资料的整理与分析。

大模型究竟能否真正提升工程师的编码效率?Anthropic 最近发布的一份重量级内部研究给出了少见的、基于真实工程环境的数据答案。研究覆盖 132 名工程师、53 场深度访谈,以及 20 万条 Claude Code 使用记录,展示了 AI 在软件工程中的实际作用:从生产力显著提升(人均合并 PR 数同比增长 67%)、任务空间扩张(27% 的 Claude 工作原本不会被执行),到工程师技能版图、协作方式与职业路径的深刻变化。与此同时,研究也揭示了技能萎缩、监督负担、工作流变化等新挑战。这是一份罕见的“

这篇文章基于 Dwarkesh Patel 对 SSI 创始人、前 OpenAI 首席科学家 Ilya Sutskever 的长访谈,系统梳理了他对模型泛化、人类智能结构、持续学习、RL 与预训练局限、超级智能路径、对齐策略,以及 AI 未来经济与治理的整体判断。文章不仅整理了核心观点,也结合具体原文展开解读,呈现 Ilya 如何从“人类为何能泛化”这一根问题出发,重新思考下一代智能系统应当如何构建。
Tool Decathlon(简称 Toolathlon)是一个针对语言代理的基准测试框架,用于评估大模型在真实环境中使用工具执行复杂任务的能力。该基准涵盖32个软件应用和604个工具,包括日常工具如 Google Calendar 和 Notion,以及专业工具如 WooCommerce、Kubernetes 和 BigQuery。它包含108个任务,每个任务平均需要约20次工具交互。该框架于2025年10月发布,旨在填补现有评测在工具多样性和长序列执行方面的空白。通过执行式评估,该基准提供可靠的性能指

几个小时前,DeepSeek 突然发布了两款全新的推理模型:DeepSeek V3.2 正式版与DeepSeek V3.2-Speciale。前者已经全面替换官方网页、App 与 API 成为新的默认模型;后者则以“临时研究 API”的方式开放,被定位为极限推理版本。

AI 能不能替我做报告”几乎成了办公室里出现频率最高的疑问之一。模型能力的提升有目共睹,API 的边界也在持续扩张,但回到日常,那些真正让人感到疲惫的依旧是最具体的任务:一份复盘写到深夜,一个 PPT 改了十几版,一张 Excel 来回分析到眼花。它们看似普通,却占据了知识工作中惊人比例的时间。本文主要看一下办公小浣熊这个颇具代表性的大模型应用落地思路。
最近 Vibe Coding 的概念越来越热,尤其是 Gemini 3 Pro 发布后,很多人都在说:“现在做网站和 App,好像一句话就能生成。” 界面生成、交互补全、流程搭建这些事情确实越来越轻松,模型能在很短时间内产出一个“看起来完整”的应用原型。一个国产开源项目就在尝试解决这个问题,它就是 AipexBase。

就在昨天,Anthropic 发布了一套非常重要的工程方案,专门针对这些挑战而设计:基于“Initializer Agent + Coding Agent”的双 Agent 架构。
本文介绍 Terminal-Bench 的设计理念,深入讲解 core、Terminal-Bench Hard 与最新 Terminal-Bench 2.0 的区别,帮助开发者选择合适的 AI 终端评测基准。

Google 最新推出的 Nano Banana Pro(Gemini 3 Pro Image) 不只是一次“图像质量提升”,而是让普通用户也能借助专业级提示词,生成具备排版、构图、品牌、摄影语言的作品。 在这个版本中,最关键的能力不是模型本身,而是: 它对结构化、专业化 Prompt 的响应能力非常强。 写对提示词,效果天差地别。 本文将完全聚焦于: 怎么写提示词,才能让 Nano Banana Pro 生出最好的图。

就在刚才,谷歌推出了 Nano Banana Pro(Gemini 3 Pro Image)。这是基于 Gemini 3 Pro 打造的专业级图像生成与编辑模型,相比几个月前的 Nano Banana,这次升级几乎重构了谷歌图像生成能力的上限。从文本渲染、多图一致性,到世界知识、摄影级控制和信息可视化,Nano Banana Pro 在多个维度显著拉开了与上一代、乃至整个行业同类产品的差距。

谷歌终于在2025年11月18日发布了新一代Gemini 3模型:Gemini 3.0 Pro。该模型目前在各个评测排行榜中都获得了非常优秀的结果,几乎是领先了所有的模型。而根据此前大家的匿名投票评分和早期测试,该模型的文本生成、编程、SVG生成等方面都非常优秀。谷歌官方强调,Gemini 3.0 Pro不仅在推理能力上达到了新的业界巅峰,更在理解深度、细微差别以及“思考”能力上实现了质的飞跃。

11 月 13 日,SimilarWeb 发布了最新的 GenAI 访问流量分布。从数据走势可以明显看到,大模型行业正在经历从“ChatGPT 绝对统治”向“多极竞争”的结构性转变。 一年前,ChatGPT 占据了超过 86% 的流量份额,整个行业几乎处于单中心状态。然而在过去的 12 个月里,大模型的多样化发展、不同厂商的产品升级、企业用户需求变化,都推动了新一轮的流量重分配。

2025 年 11 月 13 日,OpenAI 团队在 Reddit 上进行了一场针对 GPT-5.1、模型自定义能力、开发者 API、未来路线图 的公开 AMA(Ask Me Anything)。这次交流并不是简单的功能答疑,而是罕见地从内部视角解释了他们如何思考安全策略、模型行为塑形、推理模式优化、人格定制逻辑、多模态进展以及实际工程实现细节。

OpenAI 于 2025 年 11 月正式发布 GPT-5 系列的阶段性更新版本 —— GPT-5.1。这一更新并非针对模型架构的全面重做,而是围绕“对话体验、一致性、任务适配性”进行的系统化优化。在 GPT-5 推出后,业界对其不稳定回复、语气波动、任务深度控制不足等表现提出了不少批评,因此本次更新可视为 OpenAI 对这些问题的集中调整。
IMO-Bench 是 Google DeepMind 开发的一套基准测试套件,针对国际数学奥林匹克(IMO)水平的数学问题设计,用于评估大型语言模型在数学推理方面的能力。该基准包括三个子基准:AnswerBench、ProofBench 和 GradingBench,涵盖从短答案验证到完整证明生成和评分的全过程。发布于 2025 年 11 月,该基准通过专家审核的问题集,帮助模型实现 IMO 金牌级别的性能,并提供自动评分机制以支持大规模评估。

LiveBench是一个针对大型语言模型(LLM)的基准测试框架。该框架通过每月更新基于近期来源的问题集来评估模型性能。问题集涵盖数学、编码、推理、语言理解、指令遵循和数据分析等类别。LiveBench采用自动评分机制,确保评估基于客观事实而非主观判断。基准测试的总问题数量约为1000个,每月替换约1/6的问题,以维持测试的有效性。
BrowseComp是一个用于评估AI代理网页浏览能力的基准测试。它包含1266个问题,这些问题要求代理在互联网上导航以查找难以发现的信息。该基准关注代理在处理多跳事实和纠缠信息时的持久性和创造性。OpenAI于2025年4月10日发布此基准,并将其开源在GitHub仓库中。
就在今日,Moonshot AI 正式推出 Kimi K2 Thinking,这款开源思考代理模型以其革命性的工具集成和长程推理能力,瞬间点燃了开发者社区的热情。Kimi K2能自主执行200-300次连续工具调用,跨越数百步推理,解决PhD级数学难题或实时网络谜题。本次发布的Kimi K2不仅仅是模型升级,更是AI Agent能力的扩展。

让AI Agent通过编写代码来调用工具,而不是直接工具调用。这种方法利用了MCP(Model Context Protocol,模型上下文协议)标准,能显著降低token消耗,同时保持系统的可扩展性。下面,我结合原文的逻辑,分享我的理解和改写版本,目的是记录这个洞察,并为后续实验提供参考。Anthropic作为领先的AI研究机构,于2024年11月推出了MCP,这是一个开放标准,旨在简化AI Agent与外部工具和数据的连接,避免传统自定义集成的碎片化问题。