
康奈尔大学发布可以在一张消费级显卡上微调650亿参数规模大模型的框架:LLMTune
Cornell Tech开源了LLMTune,这是一个可以在消费级显卡上微调大模型的框架,经过测试,可以在48G显存的显卡上微调4bit的650亿参数的LLaMA模型!
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
Cornell Tech开源了LLMTune,这是一个可以在消费级显卡上微调大模型的框架,经过测试,可以在48G显存的显卡上微调4bit的650亿参数的LLaMA模型!

今天,HuggingFace官方宣布了Transformers最大胆的功能:Transformers Agents。这是继AutoGPT开创性发布之后,AI Agent被业界接受的另一个重要的里程碑。
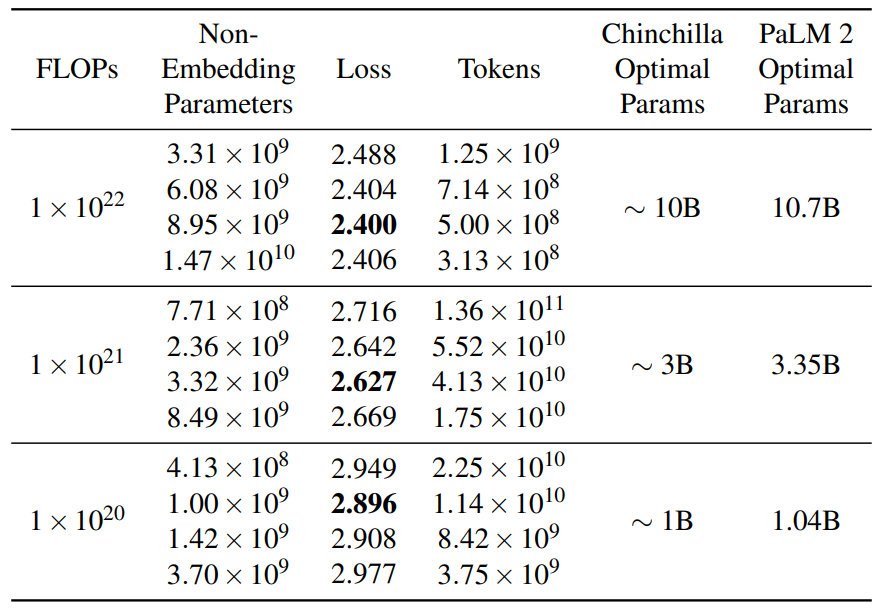
作为PaLM的继任者,PaLM2的发布被谷歌寄予厚望。与OpenAI类似,谷歌官方没有透露很多关于模型的技术细节,虽然发布了一个92页的技术报告,但是,正文内容仅仅27页,引用和作者14页,剩余51页都是展示大量的测试结果。而前面的27页内容中也没有过多的细节描述。尽管如此,这里面依然有几个十分重要的结论供大家参考。

今天,OpenAI官方宣布了一个非常有意思的论文,他们使用GPT-4模型来自动解释GPT-2中每个神经元的含义,试图让语言模型来对语言模型本身的原理进行解释。
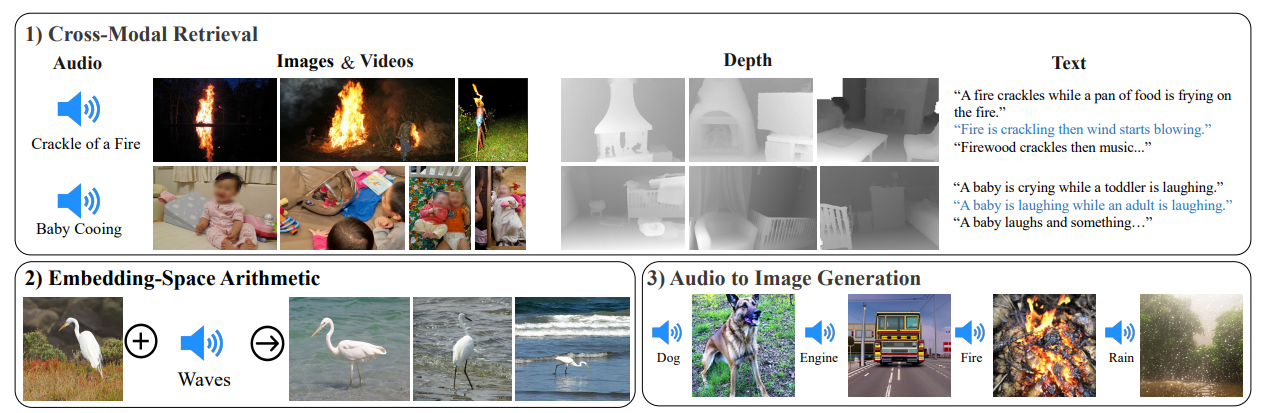
当前,大语言模型主要是基于生成式自然语言处理模型为主。少部分多模态模型可以处理文本、图片和视频信息。但是,AI模型目前还无法像人类一样接受周围的多模态信息进行处理,如图像、文本、声音等。但是,昨天MetaAI发布了一个可以听说读写的AI大模型ImageBind,它可以同时处理6种数据,并输出。本文将简单介绍一下这个模型。
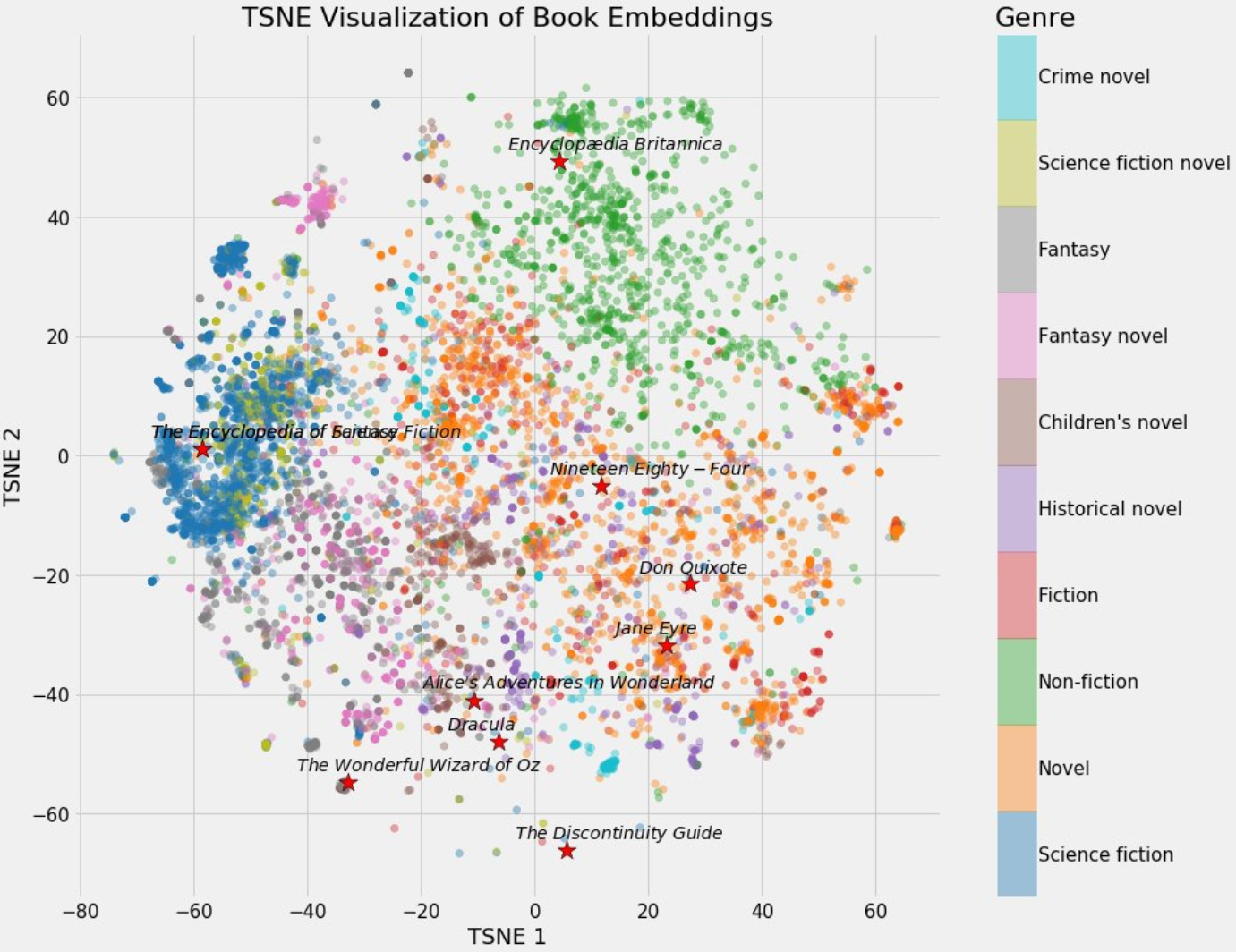
今天,推特上一位科技博主SullyOmarr分享了一个关于embedding的内容十分火爆。主要介绍为什么embedding对于在目前的AI大模型中很重要。这是一个十分不错的关于embedding知识的介绍。本文将根据SullyOmarr的内容也对embedding做一个简单的介绍,并解释为什么它在大语言模型中十分重要。

大语言模型中一个非常重要的内容就是关于代码的支持。通常,基于代码数据训练的模型不仅在代码补全方面有着更好地支持,也可能是大语言模型逻辑能力的部分来源。本文将总结目前业界专门针对代码补全(生成)方面而做的8个大模型。

昨天,开源AI模型领域迎来一个重磅玩家,MosaicML发布MPT-7B系列模型,根据官方宣布的测试结果,MPT-7B的水平与MetaAI发布的LLaMA-7B水平差不多,属于当前开源领域最强大的模型。最重要的是,MPT-7B系列中有一个可以支持最多65k上下文输入的开源模型,比GPT-4的32k还高!应该是目前最长的!
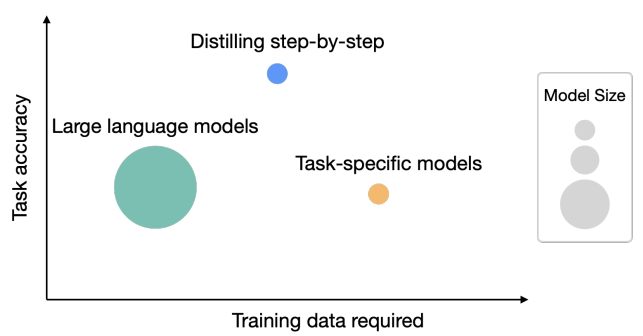
华盛顿大学研究人员与Google的研究人员一起在5月3日公布了一个新的方法,即逐步蒸馏(Distilling step-by-step),这个方法最大的特点有2个:一是需要更少的数据来做模型的蒸馏(根据论文描述,平均只需要之前方法的一半数据,最多只需要15%的数据就可以达到类似的效果);而是可以获得更小规模的模型(最多可以比原来模型规模小2000倍!)

5月4日,网络流传了一个所谓Google内部人员写的内部信,表达了Google和OpenAI这样的公司可能并不能在AI领域获得胜利的焦虑。里面说明了开源的AI模型发展迅速,不管是Google还是OpenAI都没有很好的护城河。
昨天,前苹果工程师、swift编程语言创建者Chris Lattner创立的ModularAI发布了一个新的编程语言Mojo。根据测试,该语言比Python最高提速35000倍!本文将简单介绍一下这个Mojo编程语言。
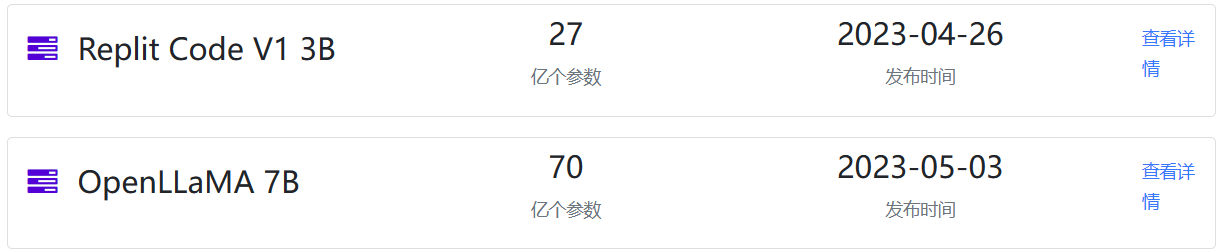
五一长假最后一天,AI技术的发展依然火热。今天有2个重磅的开源模型发布:一个是前几天提到的Replit的代码补全大模型Replit Code V1 3B,一个是UC Berkeley的博士生Hao Liu发起的一个开源LLaMA复刻项目。

2023年3月23日OpenAI官方宣布ChatGPT即将支持Plugin模式。这是一种用插件的方式来解锁ChatGPT的能力,包括让ChatGPT可以浏览网页、从本地商店订购食材等。今天,沃顿商学院教授Ethan Mollick在推特上公布了自己收到了ChatGPT内测邀请,并使用它的代码解释器(Python Interpreter)插件让ChatGPT针对一份excel数据完成了非常专业的数据分析的工作。
昨天,吴恩达宣布与OpenAI联合推出了一个新的面向开发者的ChatGPT的Prompt课程。课程主要教授大家如何使用Prompt做ChatGPT的应用开发、使用ChatGPT的新方法、建立自己的个性化的Chatbot,以及最重要的,基于OpenAI的API来练习Prompt工程技巧!
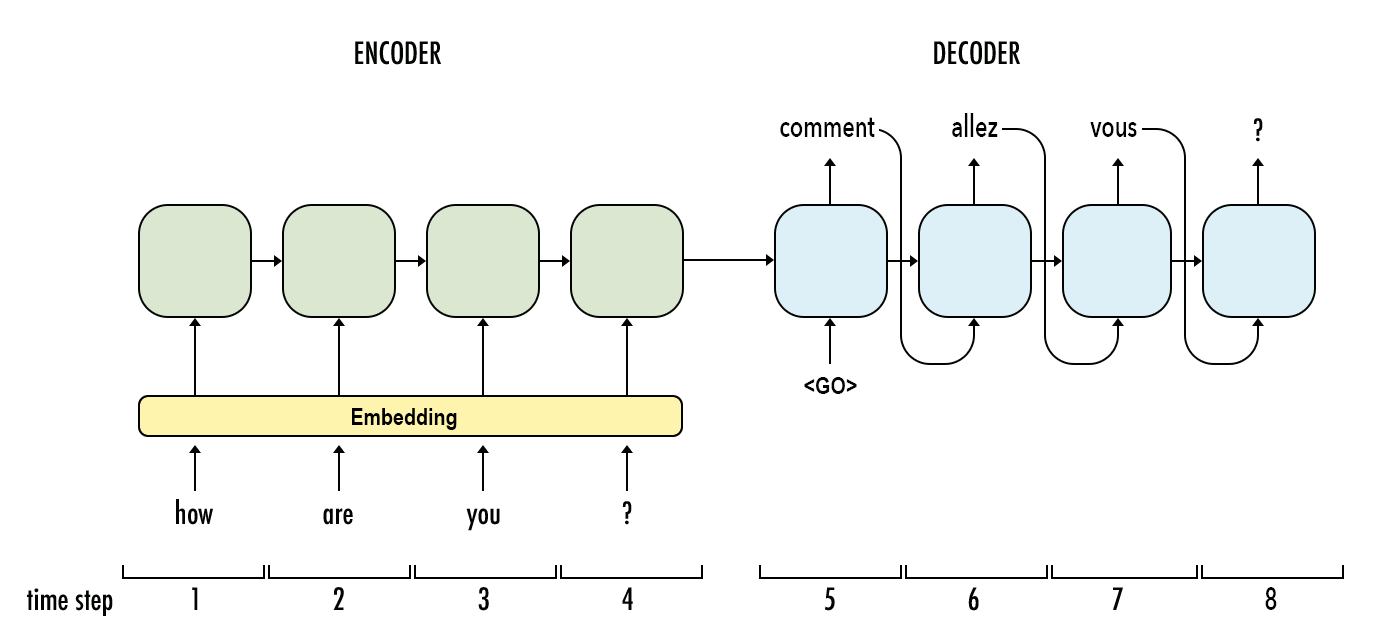
大语言模型(Large Language Model,LLM)是近几年进展最大的AI模型。早期的深度学习架构语言模型以RNN为主,现在则基本上转成了Transformer的架构。尽管如此,Transformer本身也是有着不同的区别。而本文是大语言模型系列中的一篇,主要介绍RNN模型与Transformer之间的区别。
大语言模型(Large Language Model,LLM)是近几年进展最大的AI模型。早期的深度学习架构语言模型以RNN为主,现在则基本上转成了Transformer的架构。尽管如此,Transformer本身也是有着不同的区别。而本文是大语言模型系列中的一篇,主要介绍RNN模型与Transformer之间的区别。
HuggingFace是近几年最火热的AI社区,在短短几年时间里已经称为AI模型的GitHub。目前,HuggingFace上已经托管了18万多的模型、3万多的数据集以及4万多的模型demo(spaces)。今天,HuggingFace发布了HuggingChat,声称要做最好的开源AI Chat项目,并且对所有人开放。

最近两天,关于AI技术和产品的进展依然很快。所以,我们本次直接给出一个AI技术进展快报。与大家分享一下最新的AI技术情况。
Awesome ChatGPT Prompts是由JavaScript开发者Fatih Kadir Akın创建的一个网站和应用,里面收集了160多个关于ChatGPT的Prompt模板,可以让ChatGPT变成Linux终端、JavaScript控制台、Excel页面等。这些Prompts收集自优秀的实践案例。
Whisper是OpenAI在2022年9月份开源的自动语音识别模型。官方宣传其英语的识别水平与人类接近。而2个月后,官方就发布了Whisper V2版本,是第一个版本继续训练2.5倍得到,且加了正则化技术。而今天,一位网友Sanchit Gandhi发布了Whisper JAX,这是对原有版本的优化结果,识别速度最高达到原始模型的70倍!
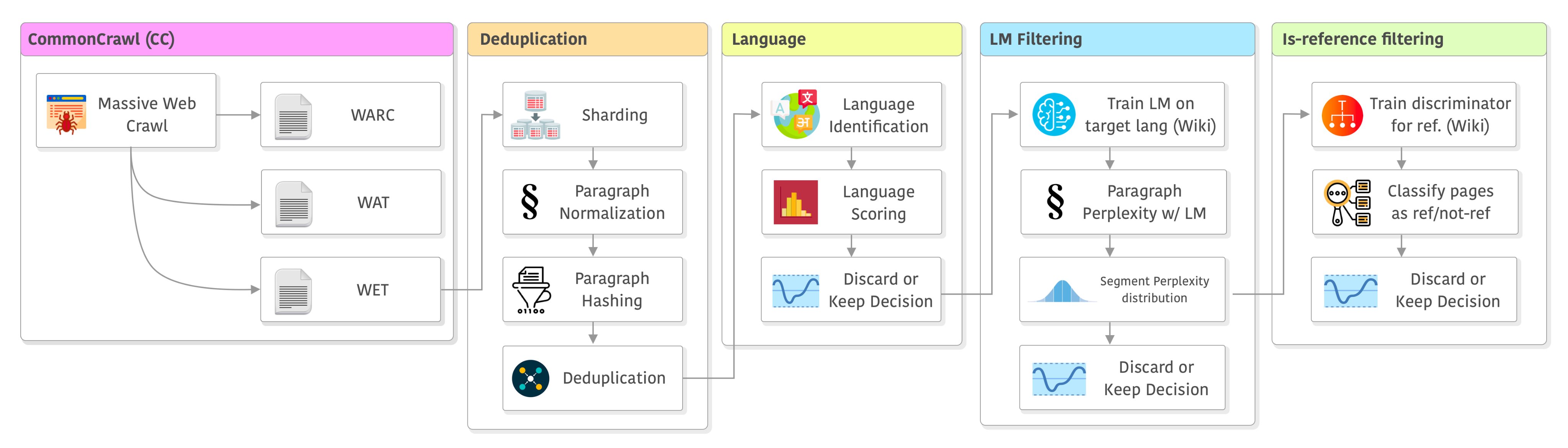
大语言模型的训练是一个十分复杂的技术,不仅涉及到模型的开发与部署,还涉及到数据的获取。与常规的算法模型不同的是,大语言模型通常需要大量的数据处理步骤。本文是根据英国一位自动工程师总结的大语言模型训练之前的数据处理步骤和决策过程。

今天下午,百度发布了文心一言大模型。这是一次对百度来说十分重要的发布会,也几乎是国内当前唯一一家将大模型作为一种大规模的服务推向市场的公司。本文主要介绍刚刚发布的文心一眼相关的能力。

在去年12月2日的PyTorch大会上(参考链接:[重磅!PyTorch官宣2.0版本即将发布,最新torch.compile特性说明!](https://www.datalearner.com/blog/1051670030665432
尽管当前ChatGPT和GPT-4非常火热,但是高昂的训练成本和部署成本其实导致大部分个人、学术工作者以及中小企业难以去开发自己的模型。使得使用OpenAI的官方服务几乎成为了一种无可替代的选择。本文介绍的是一种低成本开发高效ChatGPT的思路,我认为它适合一些科研机构去做,也适合中小企业创新的方式。这里提到的思路涉及了一些最近发表的成果和业界的一些实践产出,大家可以参考!