智谱AI发布第二代CodeGeeX编程大模型:CodeGeeX2-6B,最低6GB显存可运行,基于ChatGLM2-6B微调
编程大模型是大语言模型的一个非常重要的应用。刚刚,清华大学系创业企业智谱AI开源了最新的一个编程大模型,CodeGeeX2-6B。这是基于ChatGLM2-6B微调的针对编程领域的大模型。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
编程大模型是大语言模型的一个非常重要的应用。刚刚,清华大学系创业企业智谱AI开源了最新的一个编程大模型,CodeGeeX2-6B。这是基于ChatGLM2-6B微调的针对编程领域的大模型。

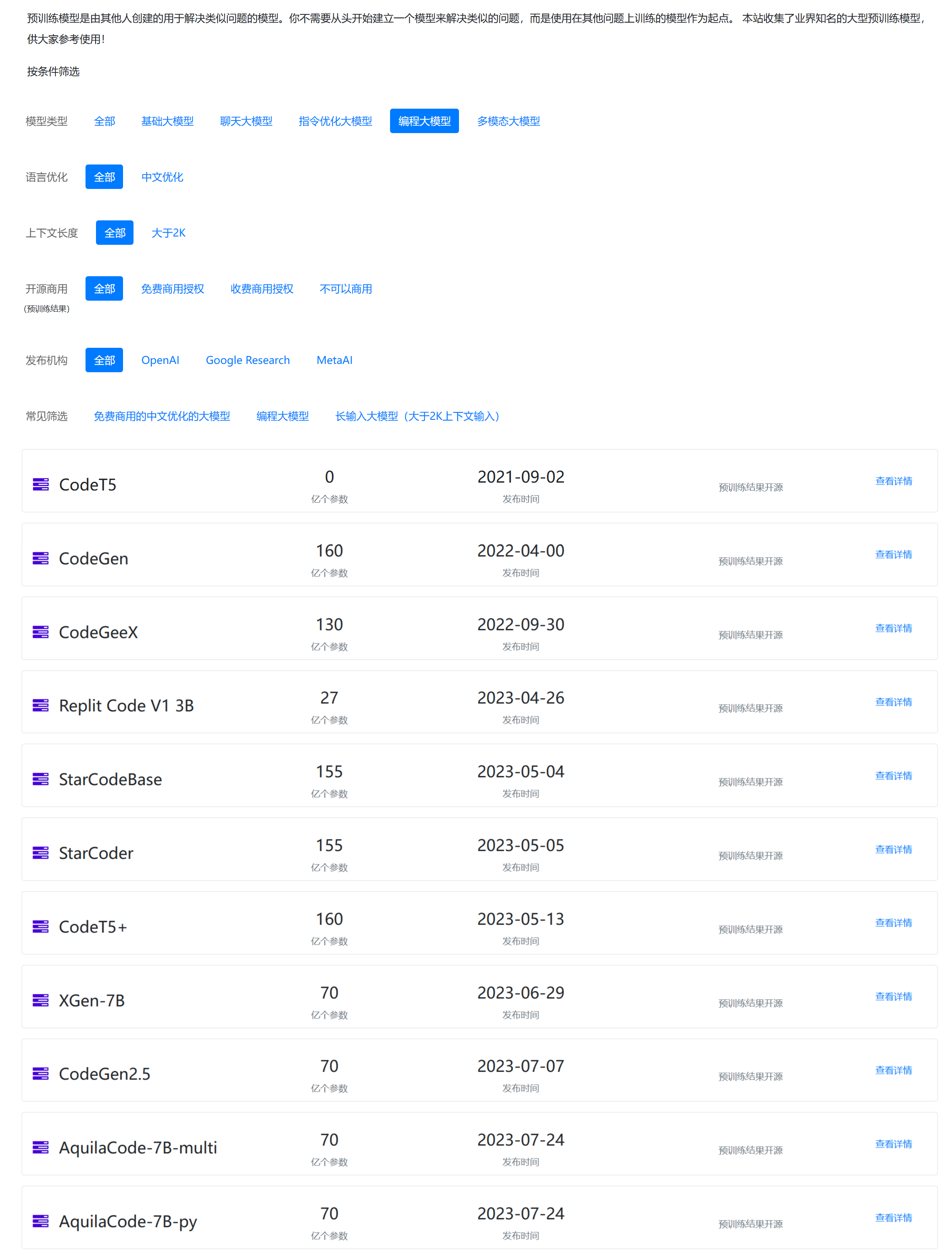
Aquila-7B是北京人工智能研究院(BAAI)开源的一个可商用大语言模型。因为其良好的推理效果和友好的商用协议,使用的人较多。今天,BAAI再次开源2个基于Aquila-7B微调的编程大模型:AquilaCode-7B-multi和AquilaCode-7B-py。

ChatGPT是最近半年多全球最火的产品。去年11月底发布之后,ChatGPT仅仅2个月时间就收获了1亿的月活。尽管在前几个月,ChatGPT是一枝独秀的存在,几乎没有任何可以与其竞争的产品与服务。然而在2023年7月份快结束的今天,市场上已经有相当多优秀的产品可供大家使用。
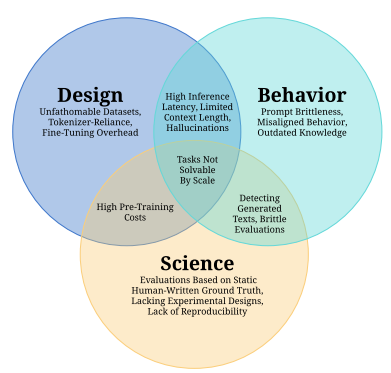
前天,EleutherAI、MetaAI、StabilityAI、伦敦大学等研究人员合作提交了一个关于大语言模型(Large Language Model,LLM)的挑战和应用的论文综述,引用了688篇参考文献总结了当前LLM的主要挑战和应用方向。

几个小时前,OpenAI官方宣布开放ChatGPT的系统指令设置功能。主要就是现在你可以为自己的ChatGPT设置一个系统级别的指令,按照你的偏好,来回复所有问题。

当前大模型本质是一种大语言模型(Large Language Models, LLM),其核心能力是对语言的处理。良好的意图识别和文本生成能力让LLM超越了之前的模型,有了巨大的实用价值。但是,现实问题涉及了很多超越语言模型之外的能力,如基于最新数据的文本摘要、向用户提供实时数据分析和可视化结果、为代码提供debugging等。目前,让LLM解决这些问题的一个最有前景的方向就是建立大模型驱动的自动代理。也就是让LLM作为核心控制者来学会使用不同工具,进而完成最终任务。

LLaMA是由Meta开源的一个大语言模型,是最近几个月一系列开源模型的基础模型。包括著名的vicuna系列、LongChat系列等都是基于该模型微调得到。可以说,LLaMA的开源促进了大模型在开源界繁荣发展。而刚刚,微软官方宣布Azure上架LLaMA2模型!这意味着LLaMA2正式发布!

ChatGPT的Code Interpreter插件让ChatGPT突破了大语言模型本身只能做文本处理的限制,使其可以通过生成并执行Python代码来实现强大的数据分析、图片生成、视频数据处理等操作,大大拓展了ChatGPT的实用范围和价值。在此前的文章中,我们已经分析了Code Interpreter插件的官方实现。而今天,LangChain的官方博客也推出了一种类似的开源方案,让开源模型也可以实现ChatGPT的Code Interperter插件。我们简要描述一下这个方案。

文本embedding是当前大模型应用中一个十分重要的角色。在长上下文支持、私有数据问答等方面有非常重要的应用。但是相比较开源领域快速发布的大模型节奏,开源的embedding模型和数据却非常少。今天,GPT4All宣布在其软件中增加embedding的支持,这是一个完全免费且可商用的产品,最重要的是可以在我们本地用CPU来做推理。
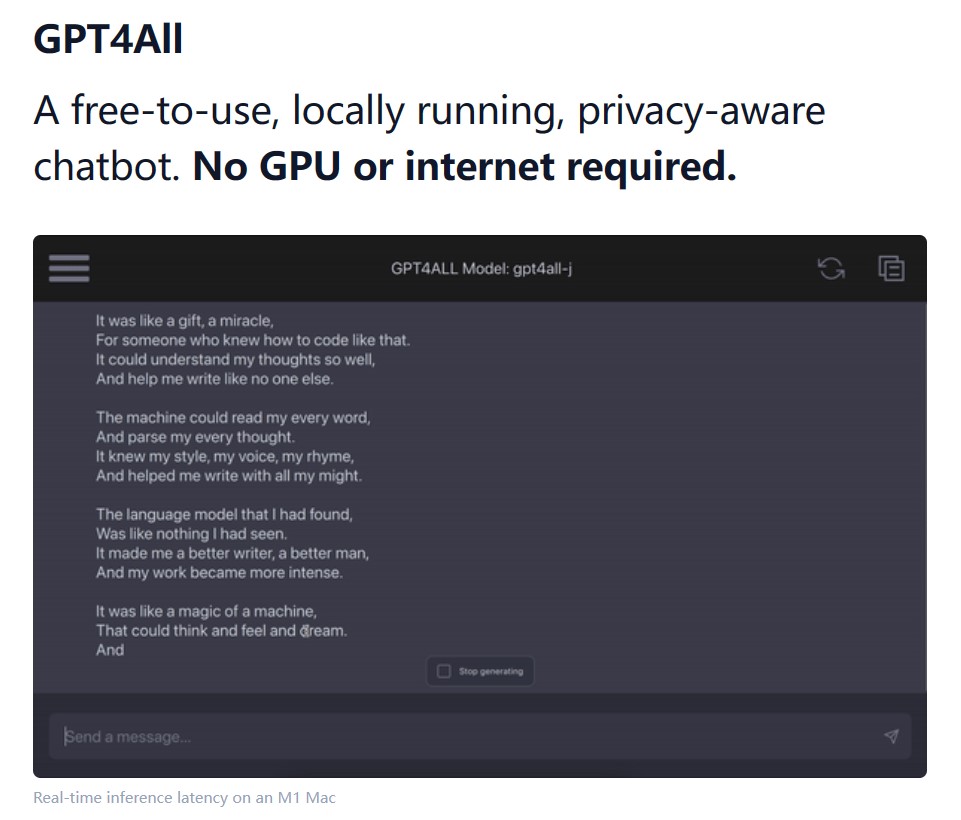
NomicAI推出了GPT4All这款软件,它是一款可以在本地运行各种开源大语言模型的软件。GPT4All将大型语言模型的强大能力带到普通用户的电脑上,无需联网,无需昂贵的硬件,只需几个简单的步骤,你就可以使用当前业界最强大的开源模型。

在七月初,ChatGLM-6B免费商用之后,ChatGLM2-6B宣布免费商用了!

Anthropic是一家专注于人工智能(AI)研究的公司,由OpenAI的前首席科学家Ilya Sutskever和Dario Amodei共同创立。Claude是Anthropic公司发布的基于transformer架构的大语言模型,被认为是最接近ChatGPT的商业产品。今天,Anthropic宣布Claude 2正式开始上架。
Code Interpreter是ChatGPT官方提供的一个插件。使用这个插件之后,ChatGPT可以通过生成Python代码来解决你的问题。在上周,Code Interperter已经完全开放给所有的付费用户,在大家使用了一段时间之后,已经有很多人通过机智的prompt来获取了Code Interpreter背后的执行环境和系统prompt信息等。本文针对这些获取的信息做一个总结,供大家参考。
几个小时前SemiAnalysis的DYLAN PATEL和DYLAN PATEL发布了一个关于GPT-4的技术信息,包括GPT-4的架构、参数数量、训练成本、训练数据集等。本篇涉及的GPT-4数据是由他们收集,并未公开数据源。但是内容还是有一定参考性,大家自行判断。

LangChain是当前大模型应用开发领域里面最火热的框架。由于其提供了丰富的数据访问接口、各种大模型的交互接口以及很多构造大模型应用所需要的方法与实践工具,受到了很多人的关注。然而,今天Hacker News上的一位开发者直接提出LangChain是一个无用的框架,引起了很多人的共鸣。很多人都表示,在实际开发中,LangChain有很多问题,可能并不适合用来做大模型应用开发。

吴恩达的DeepLearningAI在今天和LangChain的创始人一起合作发布了一个最新的基于LangChain使用LLM构建私有数据的问答系统和聊天机器人的课程(课程名:《LangChain: Chat with Your Data》)。LangChain是大语言模型应用开发领域目前最火的开源库。集成十分多的优秀特性,可以帮助我们非常简单构建LLM的应用。

大模型虽然效果很好,但是对资源的消耗却非常高。更麻烦的其实不是训练过程慢,而是峰值内存(显存)的消耗直接决定了我们的硬件是否可以来针对大模型进行训练。最近LightningAI官方总结了使用Fabric降低大模型训练内存的方法。但是,它也适用于其它场景。因此,本文总结一下相关的方法。
大语言模型的训练和微调的硬件资源要求很高。现行主流的大模型训练硬件一般采用英特尔的CPU+英伟达的GPU进行。主要原因在于二者提供了符合大模型训练所需的计算架构和底层的加速库。但是,最近苹果M2 Ultra和AMD的显卡进展让我们看到了一些新的希望。

目前开源领域已经有一些模型宣称支持了8K甚至是更长的上下文。那么这些模型在长上下文的支持上表现到底如何?最近LM-SYS发布了LongChat-7B和LangChat-13B模型,最高支持16K的上下文输入。为了评估这两个模型在长上下文的表现,他们对很多模型在长上下文的表现做了评测,让我们看看这些模型的表现到底怎么样。
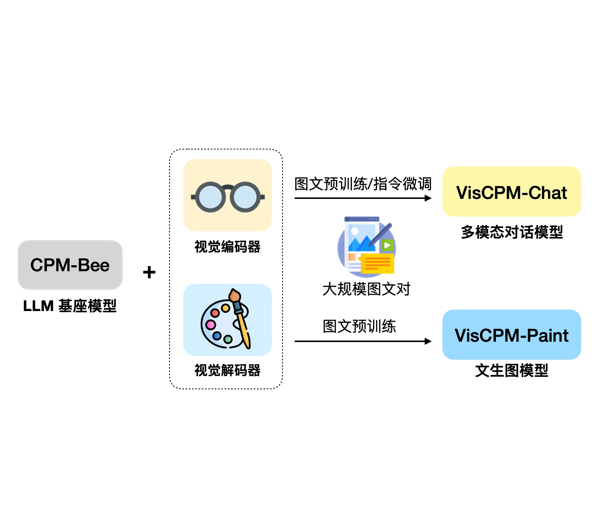
大模型的发展正在从单纯的语言模型向多模态大模型快速发展。尽管GPT-4号称也是一个多模态大模型,但是受限于GPU资源,GPT-4没有开放任何多模态的能力(参考:https://www.datalearner.com/blog/1051685866651273 )。目前大家所能接触到的多模态大模型很少。今天,清华大学NLP小组带来了新的选择,发布了VisCPM系列多模态大模型。VisCPM系列包含2类多模态大模型,分别针对多模态对话和文本生成图片进行优化。
Salesforce是全球最大的CRM企业,但是在开源大模型领域,它也是一个不可忽视的力量。今天,Salesforce宣布开源全新的XGen-7B模型,是一个同时在文本理解和代码补全任务上都表现很好的模型,在MMLU任务和代码生成任务上都表现十分优秀。最重要的是,它的2个基座模型XGen-7B-4K-Base和XGen-7B-8K-Base都是完全开源可商用的大模型。

吴恩达创办的DeepLearning.AI一直在提供各种面向AI领域的精品课程。在上个月,他们发布的四门AI短课程(包含了ChatGPT的使用、ChatGPT Prompt工程技术、面向LLM应用的LangChain教程和Diffusion工作原理)受到了广泛的欢迎。今天,吴恩达宣布与AWS的研究人员一起推出了全新的长课程《Generative AI with Large Language Models》,这门课程的主要内容是讲授生成式AI的工作原理以及如何部署面向真实世界应用的生成式AI模型。
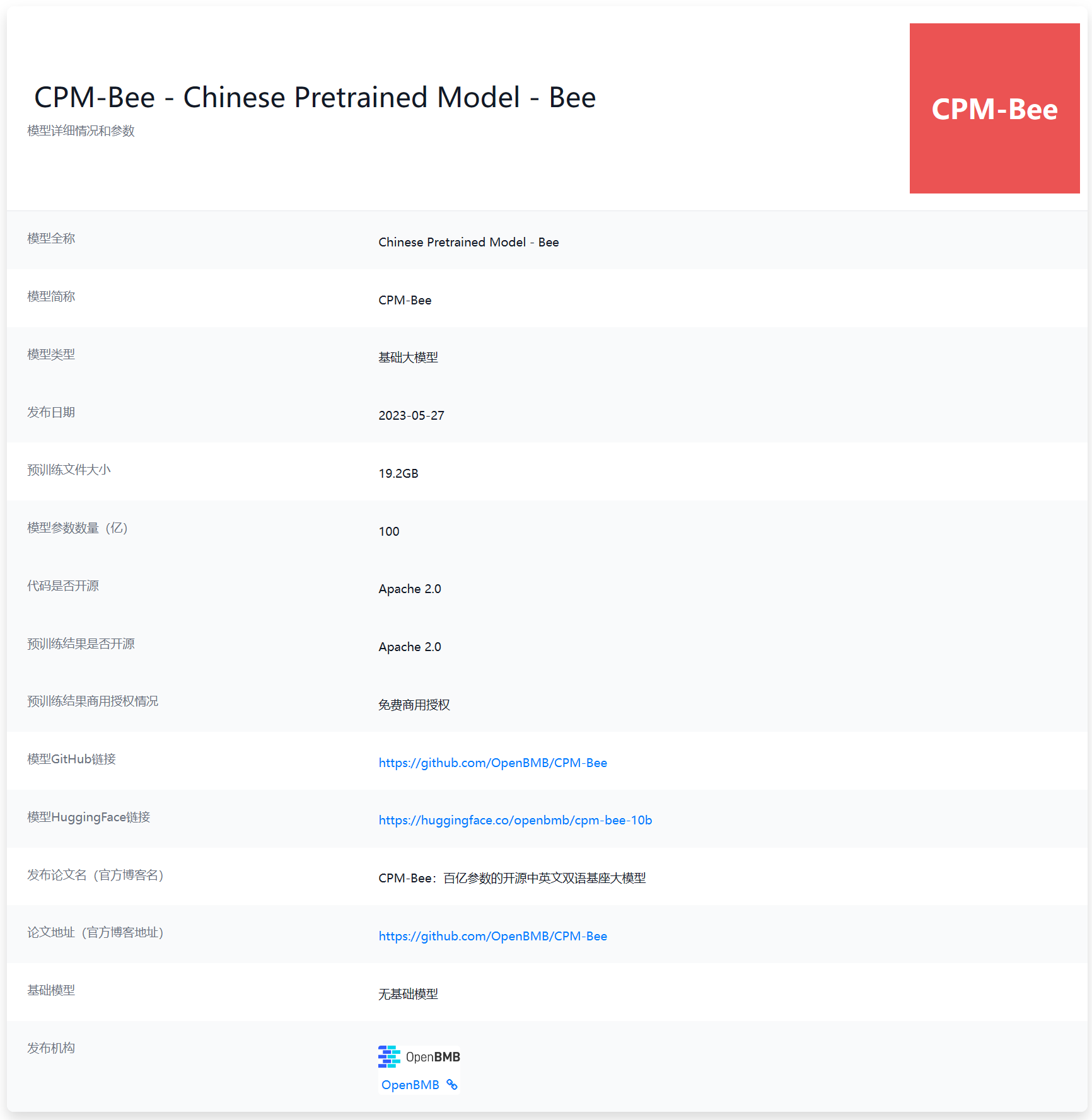
最近几个月,国产大语言模型进步十分迅速。不过,大多数企业发布的大模型均为商业产品,少数开源的LLM则有较高的商业授权费用或者商用限制。对于希望使用LLM能力的中小企业以及个人来说都不是很合适。本次给大家介绍的是目前国产开源领域里面一个十分优秀且具有潜力的大语言模型CPM-Bee 10B。该模型来自清华大学NLP实验室,参数规模100亿,最重要的是对个人和企业用户均提供免费商用授权,十分友好!