通用基座大模型是否可以超越领域专有大模型?微软最新论文证明这是可以的!微软最新动态Prompt技术——MedPrompt详解
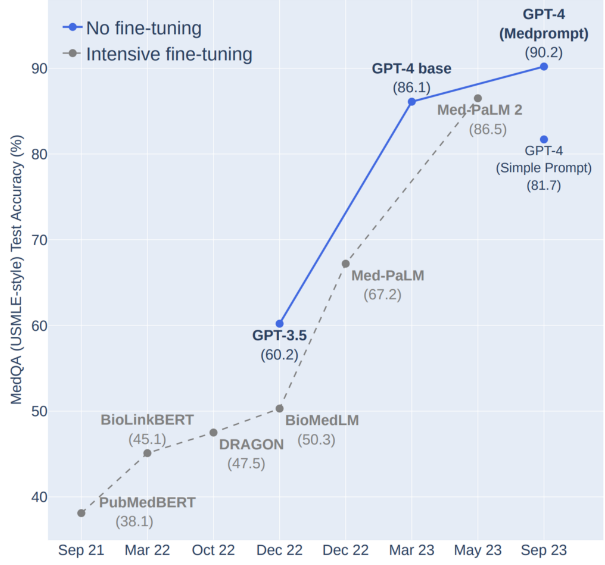
在GPT-4这种超大基座模型发布之后,一个非常活跃的方向是专有模型的发展。即一个普遍的观点认为,基座大模型虽然有很好的通用基础知识,但是对于专有的领域如医学、金融领域等,缺少专门的语料训练,因此可能表现并不那么好。如果我们使用专有数据训练一个领域大模型可能是一种非常好的思路,也是一种非常理想的商业策略。但是,微软最新的一个研究表明,通用基座大模型如果使用恰当的prompt,也许并不比专有模型差!同时,他们还提出了一个非常新颖的动态prompt生成策略,结合了领域数据,非常值得大家参考。